联想22秋招
考情分析
1. 表达式12%7的结果是
JavaScript运算符,%表示求余数
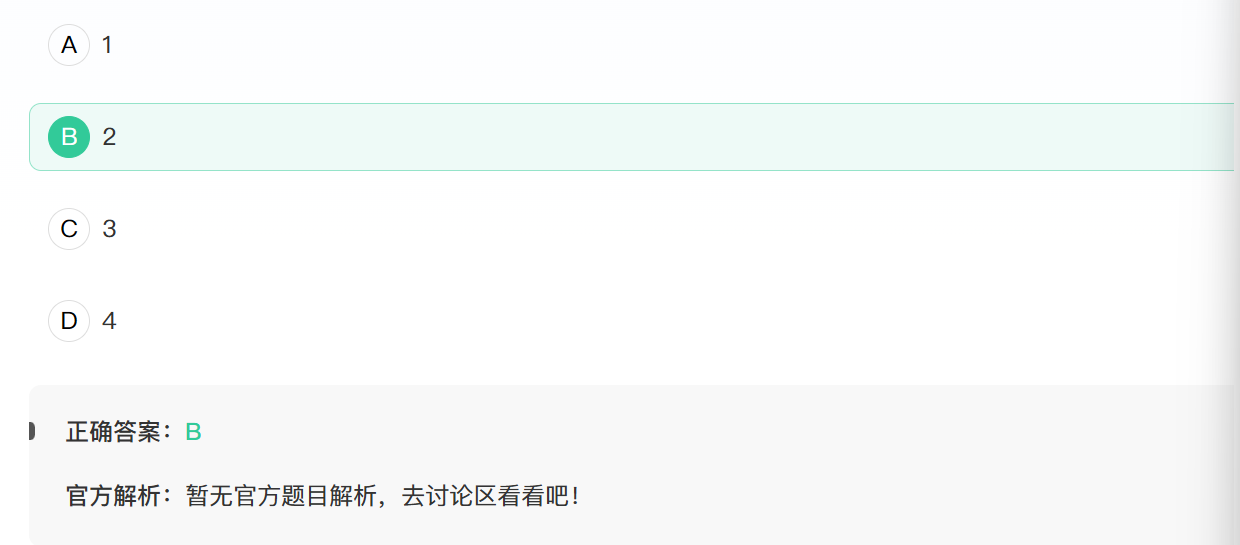
2. var num=0; num+=!num || 3;,运行以上程序后,num的值为

布尔上下文, 逻辑运算符,运算优先级,加法运算符.
首先声明num=0;0在布尔上下文中是假值,!是取非运算符,所以!num的值是true.
||是逻辑或运算符,它的规则是如果前者在布尔上下文中是真值,直接返回前者,不再进行后者的运算.
所以!num || 3的结果是true
num += true,就是num = num + true
在JavaScript中+是两种不同运算的重载:
- 数字加法
- 字符串连接
它首先它首先将两个操作数强制转换为基本类型。然后,检查两个操作数的类型:
- 如果有一方是字符串,另一方则会被转换为字符串,并且将它们连接起来。
- 如果双方都是 BigInt,则执行
BigInt加法。如果一方是BigInt而另一方不是,会抛出TypeError。 - 否则,双方都会被转换为数字,执行数字加法。
在num = num + true中,一方是number一方是boolean,所以true被转换为数字1,故num最后值为1.
真值
在在 JavaScript 中,真值是在布尔值上下文中,转换后的值为
true的值。被定义为假值以外的任何值都为真值。(即所有除false、0、-0、0n、""、null、undefined和NaN以外的皆为真值)。JavaScript 在布尔值上下文中使用强制类型转换。
JavaScript 中的真值示例如下(这些值会被强制转换为
true,因此if后的代码段将被执行):
2
3
4
5
6
7
8
9
10
11
12
13
14
if ({})
if ([])
if (42)
if ("0")
if ("false")
if (new Date())
if (-42)
if (12n)
if (3.14)
if (-3.14)
if (Infinity)
if (-Infinity)逻辑与运算 &&
如果第一个对象为真值,则逻辑与运算返回第二个操作数。
2
3
4
5
6
// 返回“狗狗”
[] && "狗狗"
// 返回“狗狗”假植
假值(
falsy,有时写为falsey)是在布尔上下文中认定为 false 的值。JavaScript 在需要用到布尔类型值的上下文中使用类型转换将值转换为布尔值,例如条件语句和循环语句。
下列表格提供了 JavaScript 的所有假值。
值 类型 描述 null Null 关键词 null— 任何值的缺失undefined Undefined undefined— 原始类型值falseBoolean 关键字 false。NaN Number NaN— 不是一个数字0Number Number零,也包括0.0、0x0等。-0Number Number负的零,也包括-0.0、-0x0等。0nBigInt BigInt零,也包括0x0n等。需要注意没有BigInt负的零 ——0n的相反数还是0n。""String 空字符串值,也包括 ''和 ````。document.allObject 唯一具有假值的 JavaScript 对象是内置的 document.all。
null和undefined也都是空值。空值
在 JavaScript 中,一个空值(nullish value)要么是
null,要么是undefined。空值总是假值。JavaScript 中假值的例子(在布尔值上下文中被转换为 false,从而绕过了
if代码块):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// 执行不到这里
}
if (null) {
// 执行不到这里
}
if (undefined) {
// 执行不到这里
}
if (0) {
// 执行不到这里
}
if (-0) {
// 执行不到这里
}
if (0n) {
// 执行不到这里
}
if (NaN) {
// 执行不到这里
}
if ("") {
// 执行不到这里
}逻辑与操作符 &&
如果第一个对象是假值,则返回那个对象:
2
3
4
5
6
// ↪ false
console.log(0 && "dog");
// ↪ 0
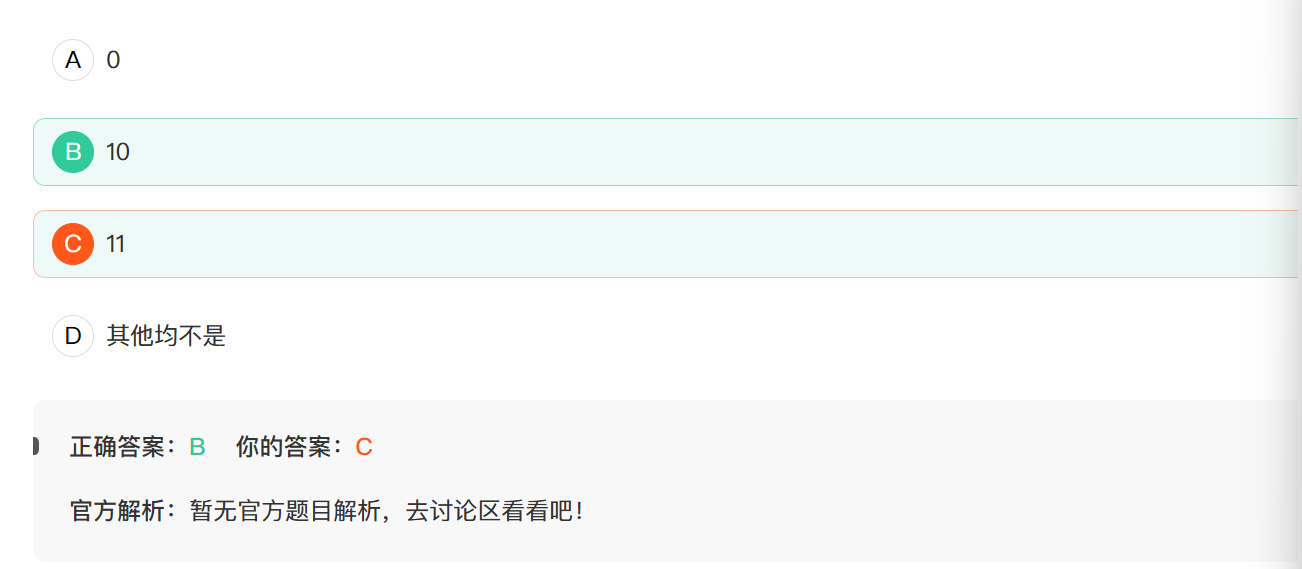
3. var x, y = 0; x=10; y=x++;运行以上程序后,y的值为
++
y=x++是先把x的值赋给y,在让x=x+1
y=++x是先让x=x+1,再赋值给y
4. 下列表示的存储容量最小的是()
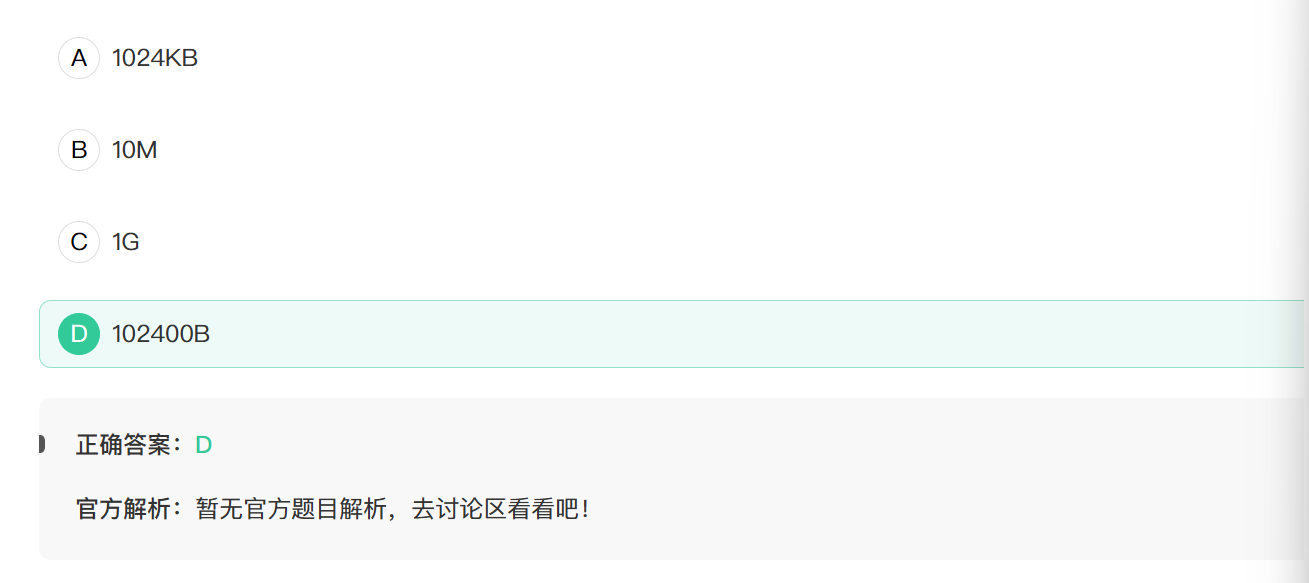
1B = 8 bit
1KB = 2^10B = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
5. HTTP协议是()
6. ES6中定义let[a=3,b=a,c=b]=[1,2];a,b,c的值分别是
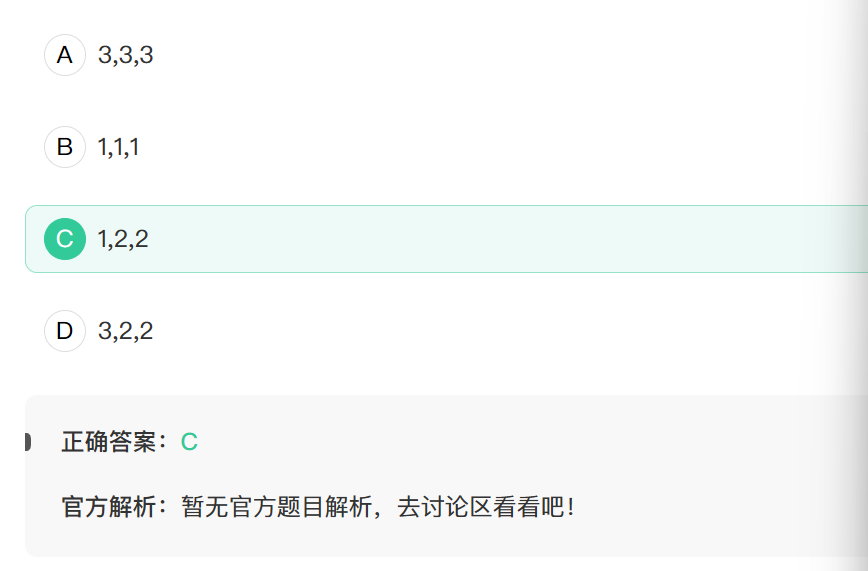
解构赋值
a=3,b=a,c=b这些是解构赋值中的默认值,只有在右边对应值为undefined这一种情况下会使用默认值,其他情况使用右边的对应值.
这里先给a赋值1,然后又给b赋值2,c对应的值是undefined,使用默认值b,这里要用临近作用域的b,也就是刚才刚更新的2,所以c的值为2.
综上1,2,2.
7. 在日常生活中,我们经常会定义商品的价格,是由数字和小数点组成。下面能完全覆盖0~10000(不含10000)的整数或2位以内小数的正则表达式是
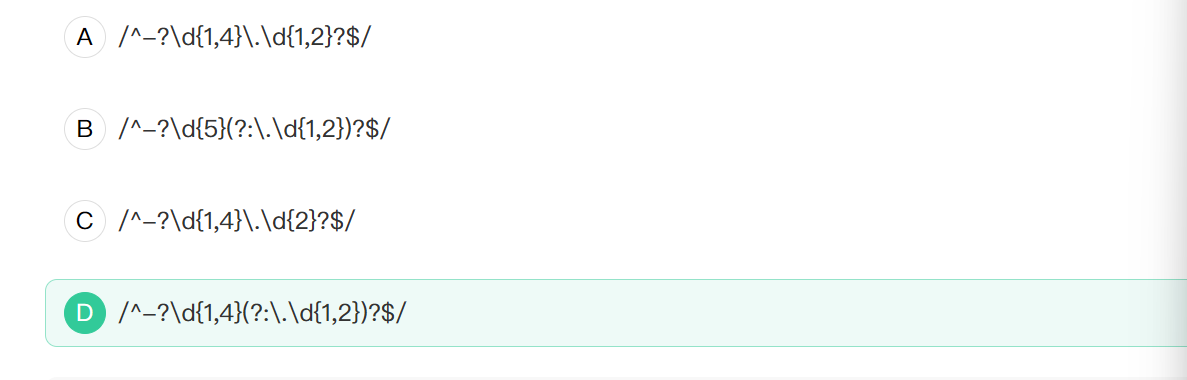
正则表达式
正则表达式是用于匹配字符串中字符组合的模式.在JavaScript中,正则表达式也是对象.这些模式被用于这些模式被用于 RegExp 的 exec 和 test 方法,以及 String 的 match、matchAll、replace、search 和 split 方法。本章介绍 JavaScript 正则表达式。
创建正则表达式
你可以用以下两种方法构建一个正则表达式:
使用一个正则表达式字面量,其由包含在斜杠之间的模式组成,如下
1 | var re = /ab+c/; |
脚本加载后,正则表达式就会被编译.当正则表达式保持不变时,使用此方法可获得更好的性能.
或者调用RegExp对象的构造函数,如下所示:
1 | var re = new RegExp("ab+c"); |
在脚本运行过程中,用构造函数创建的正则表达式会被编译。如果正则表达式将会改变,或者它将会从用户输入等来源中动态地产生,就需要使用构造函数来创建正则表达式.
一个正则表达式模式是由简单的字符所构成的,比如 /abc/;或者是简单和特殊字符的组合,比如 /ab*c/ 或 /Chapter (\d+)\.\d*/。最后的例子中用到了括号,它在正则表达式中常用作记忆设备。即这部分所匹配的字符将会被记住以备后续使用,例如使用括号的子字符串匹配。
使用简单模式
简单模式是由你想直接找到的字符构成.比如,/abc/这个模式就能且仅能匹配”abc”字符按照顺序同时出现的情况.例如在 “Hi, do you know your abc’s?” 和 “The latest airplane designs evolved from slabcraft.” 中会匹配成功。在上述两个例子中,匹配的子字符串是 “abc”。但是在 “Grab crab” 中会匹配失败,因为它虽然包含子字符串 “ab c”,但并不是准确的 “abc”。
使用特殊字符
当你需要匹配一个不确定的字符串时,比如寻找一个或多个 “b”,或者寻找空格,可以在模式中使用特殊字符。比如,你可以使用 /ab*c/ 去匹配一个单独的 “a” 后面跟了零个或者多个 “b”,同时后面跟着 “c” 的字符串:*的意思是前一项出现零次或者多次。在字符串 “cbbabbbbcdebc” 中,这个模式匹配了子字符串 “abbbbc”。
下面的页面与表格列出了一个正则表达式中可以利用的特殊字符的完整列表和描述。
断言指南
表示一个匹配在某些条件下发生。断言包含先行断言、后行断言和条件表达式。
字符类指南
区分不同类型的字符,例如区分字母和数字。
组和反向引用指南
当使用正则表达式模式与字符串匹配时,组会将多个模式组合成一个整体,捕获组会提供额外的子匹配信息。反向引用指的是同一正则表达式中以前捕获的组。
量词指南
表示匹配的字符或表达式的数量。
| 字符 | 含义 |
| ———— | —————————————————————————————— |
|\| 依照下列规则匹配
在非特殊字符之前的反斜杠表示下一个字符是特殊字符,不能按照字面理解.例如,前面没有\的b通常匹配小写字母”b”,即字符会被作为字面理解,无论它出现在哪里.但如果前面加了\,它将不再匹配任何字符,而是表示一个字符边界。
在特殊字符之前的反斜杠表示下一个字符不是特殊字符,应该按照字面理解。详情请参阅下文中的 “转义(Escaping)” 部分。
如果你想将字符串传递给RegExp构造函数,不要忘记在字符串字面量中反斜杠是转义字符.所以为了在模式中添加一个反斜杠,你需要在字符串字面量中转义它./[a-z]\s/i和new RegExp("[a-z]\\s","i")创建了相同的正则表达式:一个用于搜索后面跟着空白字符(\s可看后文)并且在a-z范围内的任意字符的表达式.为了通过字符串字面量给RegExp构造函数创建包含反斜杠的表达式,你需要在字符串级别和正则表达式级别都对他进行转义.例如/[a-z]:\\/i和new RegExp("[a-z]:\\\\","i")会创建相同的表达式,即匹配类似”C:\“的字符串. |
|^| 匹配输入的开始.如果多行标志被设置为true,那么也匹配换行符后紧跟的位置
例如/^A/并不会匹配”an A”中的”A”,但是会匹配”An E”中的’A’
当 ‘^‘ 作为第一个字符出现在一个字符集合模式时,它将会有不同的含义。反向字符集合 一节有详细介绍和示例。 |
|$| 匹配输入的结束。如果多行标志被设置为 true,那么也匹配换行符前的位置。
例如,/t$/并不会匹配 “eater” 中的 ‘t’,但是会匹配 “eat” 中的 ‘t’。 |
|*| 匹配前一个表达式 0 次或多次。等价于{0,}。
例如,/bo*/会匹配 “A ghost boooooed” 中的 ‘booooo’ 和 “A bird warbled” 中的 ‘b’,但是在 “A goat grunted” 中不会匹配任何内容。 |
|+| 匹配前面一个表达式 1 次或者多次。等价于{1,}。
例如,/a+/会匹配 “candy” 中的 ‘a’ 和 “caaaaaaandy” 中所有的 ‘a’,但是在 “cndy” 中不会匹配任何内容。 |
|?| 匹配前面一个表达式 0 次或者 1 次。等价于{0,1}。
例如,/e?le?/匹配 “angel” 中的 ‘el’、”angle” 中的 ‘le’ 以及 “oslo’ 中的 ‘l’。
如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 “123abc” 使用/\d+/将会匹配 “123”,而使用/\d+?/则只会匹配到 “1”。
还用于先行断言中,如本表的x(?=y)和x(?!y)条目所述。 |
|.| (小数点)默认匹配除换行符之外的任何单个字符。
例如,/.n/将会匹配 “nay, an apple is on the tree” 中的 ‘an’ 和 ‘on’,但是不会匹配 ‘nay’。
如果s(“dotAll”) 标志位被设为 true,它也会匹配换行符。 |
|(x)| 像下面的例子展示的那样,它会匹配 ‘x’ 并且记住匹配项。其中括号被称为捕获括号。
模式/(foo) (bar) \1 \2/中的 ‘(foo)‘ 和 ‘(bar)‘ 匹配并记住字符串 “foo bar foo bar” 中前两个单词。模式中的\1和\2表示第一个和第二个被捕获括号匹配的子字符串,即foo和bar,匹配了原字符串中的后两个单词。注意\1、\2、…、\n是用在正则表达式的匹配环节,详情可以参阅后文的 \n 条目。而在正则表达式的替换环节,则要使用像$1、$2、…、$n这样的语法,例如,'bar foo'.replace(/(...) (...)/, '$2 $1')。$&表示整个用于匹配的原字符串。 |
|(?:x)| 匹配’x’但是不记住匹配项.这种括号叫做非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式.看看这个例子/(?:foo){1,2}/.如果表达式是/foo{1,2},{1,2}将只会应用于’foo’的最后一个字符’o’.如果使用非捕获括号,则{1,2}会应用于整个foo单词.更多信息,可以参阅下文的 使用括号的子字符串匹配 条目。 |
A. /^-?\d{1,4}\.\d{1,2}?$/
^-?表示以负号-开头,但是可以没有,因为?表示0次或1次.在本题其实没必要匹配负数.
\d{1,4},\d匹配一个数字,等价于[0-9],{n,m}表示匹配前面的字符至少n次,最多m次.即闭区间.所以表示匹配数字(一位数到四位数).
.本身默认匹配的是除了换行符外的任意一个字符.但是在使用\转以后,就表示字面量意思.\.就是表示一个点.而题目要求可能是整数,也可能是小数.所以A,C选项中强制匹配小数点,不符合.
B. /^-?\d{5}(?:\.\d{1,2})?$/
B中匹配5位数字,不符.
D中的(?:)是非匹配括号,后面跟一个?表示可有可无.最后$表示结尾,符合预期.
8. new Date(2020,12,1).getMonth()的结果是?
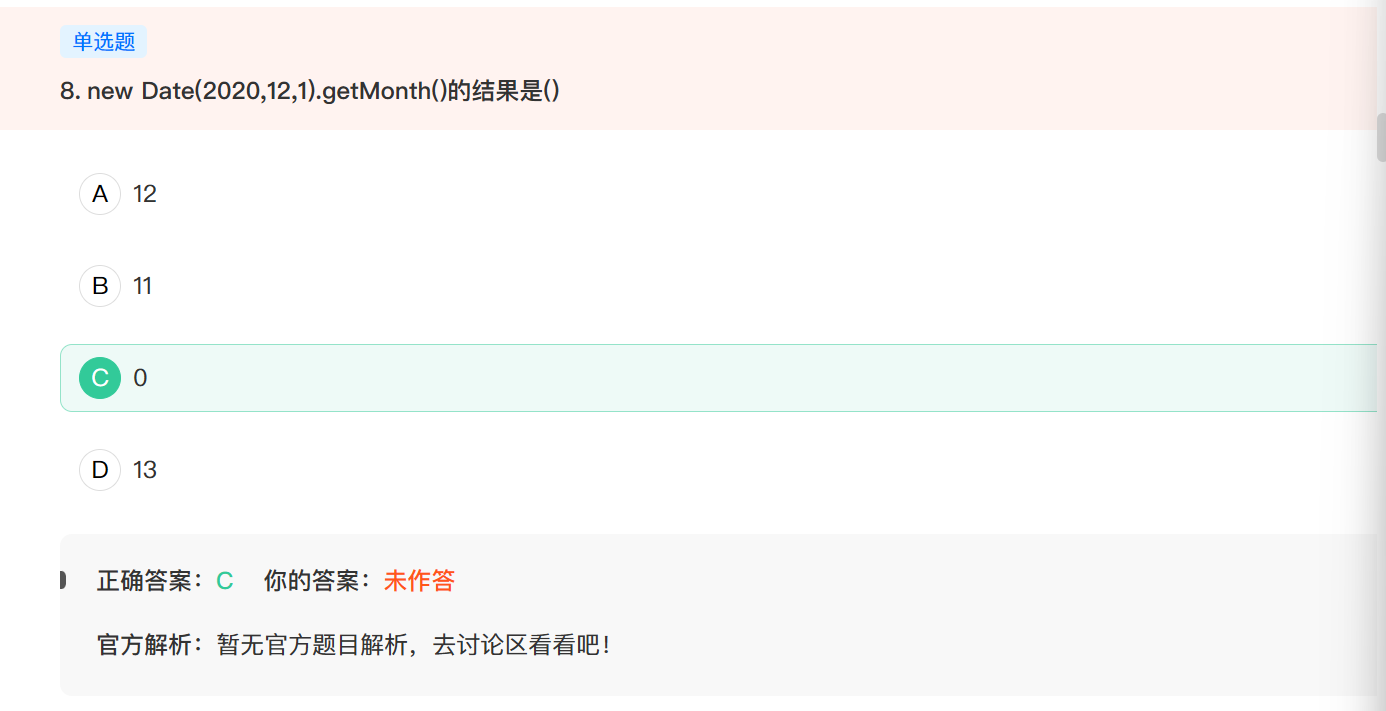
Date对象
在JS中的Date对象的Month是从0开始计数的,0-11分别表示一到十二月.所以在传入2020,12,1会自动模12运算,变为2021年1月1日.所以输出是0.
9. 下列那个函数会改变原数组的值
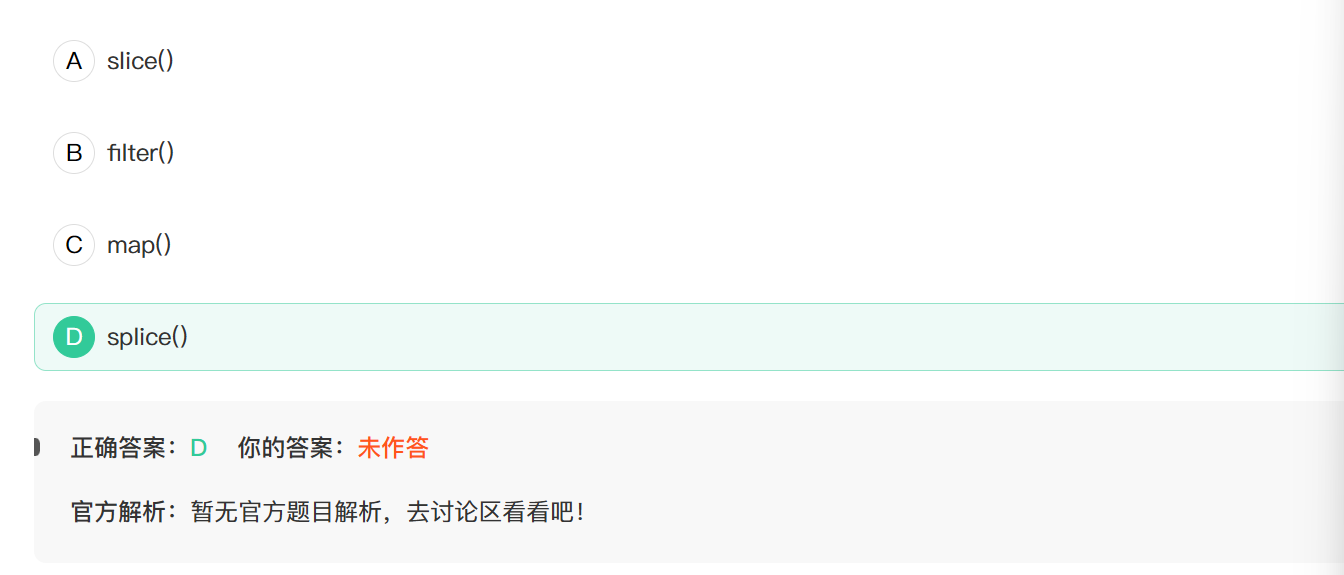
slice() 方法返回一个新的数组对象,这一对象是一个由 start 和 end 决定的原数组的浅拷贝(包括 start,不包括 end),其中 start 和 end 代表了数组元素的索引。原始数组不会被改变。
slice是浅拷贝,左闭右开
语法
1 | slice() |
参数
start(可选)
提取起始处的索引(从0开始),会转换为整数。
- 如果索引是负数,则从数组末尾开始计算——如果
start < 0,则使用start + array.length。 - 如果
start < -array.length或者省略了start,则使用0。 - 如果
start >= array.length,则不提取任何元素。
end(可选)
提取终止处的索引(从 0 开始),会转换为整数。slice() 会提取到但不包括 end 的位置。
- 如果索引是负数,则从数组末尾开始计算——如果
end < 0,则使用end + array.length。 - 如果
end < -array.length,则使用0。 - 如果
end >= array.length或者省略了end,则使用array.length,提取所有元素直到末尾。 - 如果
end在规范化后小于或等于start,则不提取任何元素。
返回值
一个含有被提取元素的新数组
slice() 方法是一个复制方法。它不会改变 this,而是返回一个浅拷贝,其中包含了原始数组的一部分相同的元素。
slice() 方法会保留空槽。如果被切片的部分是稀疏的,则返回的数组也是稀疏的。
slice() 方法是通用的。它只要求 this 上有 length 属性和整数键属性。
filter() 方法创建给定数组一部分的浅拷贝,其包含通过所提供函数实现的测试的所有元素。
语法
1 | filter(callbackFn) |
参数
-
为数组中的每个元素执行的函数。它应该返回一个真值以将元素保留在结果数组中,否则返回一个假值。该函数被调用时将传入以下参数:
element数组中当前正在处理的元素。index正在处理的元素在数组中的索引。array调用了filter()的数组本身。 -
执行
callbackFn时用作this的值。参见迭代方法。
返回值
返回给定数组的一部分的浅拷贝,其中只包括通过提供的函数实现的测试的元素。如果没有元素通过测试,则返回一个空数组。
filter() 方法是一个迭代方法。它为数组中的每个元素调用提供的 callbackFn 函数一次,并构造一个由所有返回真值的元素值组成的新数组。未通过 callbackFn 测试的数组元素不会包含在新数组中。
callbackFn 仅对已分配值的数组索引调用。它不会对稀疏数组中的空槽调用。
filter() 方法是一个复制方法。它不会改变 this,而是返回一个包含与原始数组相同的元素(其中某些元素已被过滤掉)的浅拷贝。但是,作为 callbackFn 的函数可以更改数组。请注意,在第一次调用 callbackFn 之前,数组的长度已经被保存。因此:
- 当开始调用
filter()时,callbackFn将不会访问超出数组初始长度的任何元素。 - 对已访问索引的更改不会导致再次在这些元素上调用
callbackFn。 - 如果数组中一个现有的、尚未访问的元素被
callbackFn更改,则它传递给callbackFn的值将是该元素被修改后的值。被删除的元素则不会被访问。
map() 方法创建一个新数组,这个新数组由原数组中的每个元素都调用一次提供的函数后的返回值组成。
语法
1 | map(callbackFn) |
参数
-
为数组中的每个元素执行的函数。它的返回值作为一个元素被添加为新数组中。该函数被调用时将传入以下参数:
element数组中当前正在处理的元素。index正在处理的元素在数组中的索引。array调用了map()的数组本身。 -
执行
callbackFn时用作this的值。参见迭代方法。
返回值
一个新数组,每个元素都是回调函数的返回值。
map() 方法是一个迭代方法。它为数组中的每个元素调用一次提供的 callbackFn 函数,并用结果构建一个新数组。
callbackFn 仅在已分配值的数组索引处被调用。它不会在稀疏数组中的空槽处被调用。
map() 方法是一个复制方法。它不会改变 this。然而,作为 callbackFn 提供的函数可以更改数组。请注意,在第一次调用 callbackFn 之前,数组的长度已经被保存。因此:
- 当开始调用
map()时,callbackFn将不会访问超出数组初始长度的任何元素。 - 对已访问索引的更改不会导致再次在这些元素上调用
callbackFn。 - 如果数组中一个现有的、尚未访问的元素被
callbackFn更改,则它传递给callbackFn的值将是该元素被修改后的值。被删除的元素则不会被访问。
map() 方法是通用的。它只期望 this 值具有 length 属性和整数键属性。
由于 map 创建一个新数组,在没有使用返回的数组的情况下调用它是不恰当的;应该使用 forEach 或 for...of 作为代替。
splice() 方法就地移除或者替换已存在的元素和/或添加新的元素。
要创建一个删除和/或替换部分内容而不改变原数组的新数组,请使用 toSpliced()。要访问数组的一部分而不修改它,参见 slice()。
1 | splice(start) |
参数
-
从 0 开始计算的索引,表示要开始改变数组的位置,它会被转换成整数。负索引从数组末尾开始计算——如果
-buffer.length <= start < 0,使用start + array.length。如果start < -array.length,使用0。如果start >= array.length,则不会删除任何元素,但是该方法会表现为添加元素的函数,添加所提供的那些元素。如果start被省略了(即调用splice()时不传递参数),则不会删除任何元素。这与传递undefined不同,后者会被转换为0。 -
一个整数,表示数组中要从
start开始删除的元素数量。如果省略了deleteCount,或者其值大于或等于由start指定的位置到数组末尾的元素数量,那么从start到数组末尾的所有元素将被删除。但是,如果你想要传递任何itemN参数,则应向deleteCount传递Infinity值,以删除start之后的所有元素,因为显式的undefined会转换为0。如果deleteCount是0或者负数,则不会移除任何元素。在这种情况下,你应该至少指定一个新元素(请参见下文)。 -
从
start开始要加入到数组中的元素。如果不指定任何元素,splice()将只从数组中删除元素。
返回值
一个包含了删除的元素的数组。
如果只移除一个元素,则返回一个元素的数组。
如果没有删除任何元素,则返回一个空数组。
splice() 方法是一个修改方法。它可能会更改 this 的内容。如果指定的要插入的元素数量与要删除的元素数量不同,数组的 length 也将会更改。同时,它会使用 [Symbol.species\] 来创建一个新数组实例并返回。
如果删除的部分是稀疏的,则 splice() 返回的数组也是稀疏的,对应的索引为空槽。
splice() 方法是通用的。它只期望 this 值具有 length 属性和整数键属性。尽管字符串也类似于数组,但这种方法不适用于它,因为字符串是不可变的。
10. 以下关于深拷贝和浅拷贝的说法错误的是?
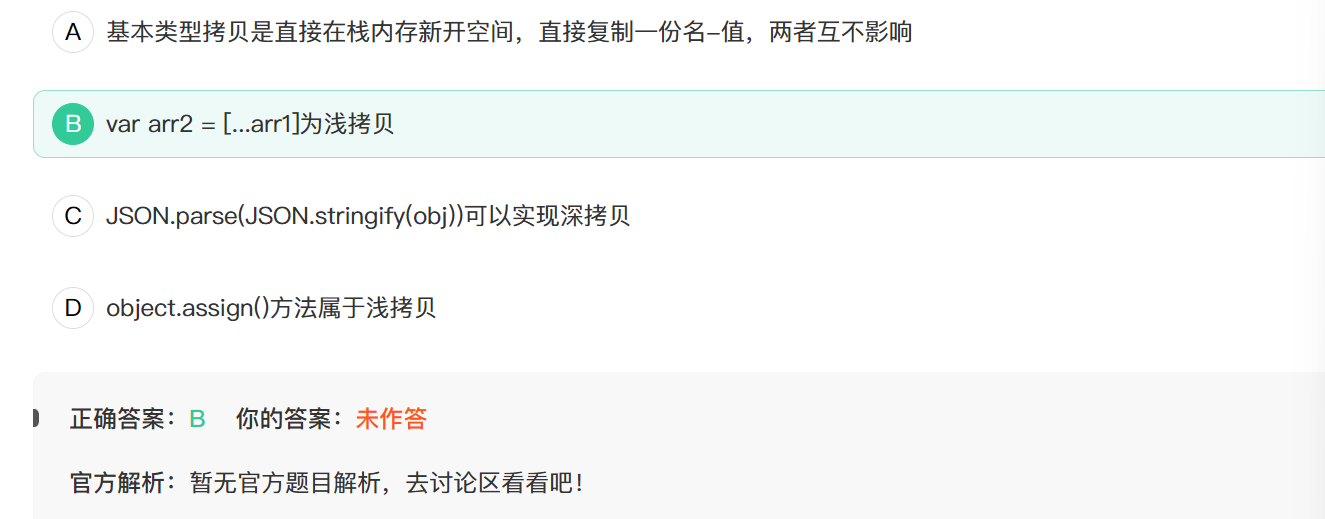
深拷贝和浅拷贝
注意:此题题解错误,正确答案应该是C!!!
展开运算符确实是浅拷贝,B的说法没问题,本题选择错误的,应该选C.因为许多 JavaScript 对象根本不能序列化——例如,函数(带有闭包)、Symbol、在 HTML DOM API 中表示 HTML 元素的对象、递归数据以及许多其他对象。在这种情况下,调用
JSON.stringify()来序列化对象将会失败。所以没有办法对这些对象进行深拷贝。
深拷贝
对象的深拷贝是指属性与其拷贝的源对象的属性不共享相同的引用(指向相同的底层值)的副本.因此,当你更改源或副本时,可以确保不会导致其他对象也发生更改;也就是说,你不会无意中对源或副本造成意料之外的更改.这种行为与浅拷贝的行为形成对比,在浅拷贝中,对源或副本的更改可能也会导致其他对象的更改(因为两个对象共享相同的引用)。
如果两个对象o1和o2是结构等价的,那么他们的观察行为是相同的.这些行为包括:
o1和o2的属性具有相同的名称且顺序相同- 他们的属性的值是结构等价的
- 它们的原型链是结构等价的(尽管在处理结构等价时,这些对象通常是普通对象,意味着他们都继承自
Object.prototype)
解构等价的对象可以是同一个对象(o1===o2)或副本(o1!==o2).因为等价的原始值总是相等的,所以你无法对他们进行复制.
我们现在可以更正式地定义深拷贝
- 他们不是同一个对象(
o1!==o2) o1和o2的属性具有相同的名称且顺序相同- 他们的属性的值是彼此的深拷贝
- 他们的原型链是结构等价的.
深拷贝可能会或可能不会复制他们的原型链(通常情况下不会).但是,具有结构不等价原型链的两个对象(例如,一个是数组,另一个是普通对象)永远不会是彼此的副本.
所有属性都具有原始值的对象的副本符合深拷贝和浅拷贝的定义。然而,讨论这种副本的深度并无意义,因为它没有嵌套属性,而我们通常在改变嵌套属性的上下文中讨论深拷贝。
在 JavaScript 中,标准的内置对象复制操作(展开语法、Array.prototype.concat()、Array.prototype.slice()、Array.from()、Object.assign() 和 Object.create())不创建深拷贝(相反,它们创建浅拷贝)。
如果一个 JavaScript 对象可以被序列化,则存在一种创建深拷贝的方式:使用 JSON.stringify() 将该对象转换为 JSON 字符串,然后使用 JSON.parse() 将该字符串转换回(全新的)JavaScript 对象:
1 | let ingredients_list = ["noodles", { list: ["eggs", "flour", "water"] }]; |
由于深拷贝与其源对象不共享引用,因此对深拷贝所做的任何更改都不会影响源对象。
1 | // 改变 ingredients_list_deepcopy 中“list”属性的值。 |
然而,虽然上面代码中的对象足够简单,可以序列化,但许多 JavaScript 对象根本不能序列化——例如,函数(带有闭包)、Symbol、在 HTML DOM API 中表示 HTML 元素的对象、递归数据以及许多其他对象。在这种情况下,调用 JSON.stringify() 来序列化对象将会失败。所以没有办法对这些对象进行深拷贝。
你也可以使用 Web API structuredClone() 来创建深拷贝。structuredClone() 的优点是允许源代码中的可转移对象被转移到新的副本,而不仅仅是克隆。它还能处理更多的数据类型,如 Error。但是请注意,structuredClone() 不是 JavaScript 语言本身的特性——相反,它是浏览器和任何其他实现了 window 这样全局对象的 JavaScript 运行时的一个特性。调用 structuredClone() 来克隆一个不可序列化的对象,与调用 JSON.stringify() 来序列化一个不可序列化的对象一样,会失败。
浅拷贝
对象的浅拷贝是属性与拷贝的源对象属性共享相同的引用(指向相同的底层值)的副本。因此,当你更改源对象或副本时,也可能导致另一个对象发生更改。与之相比,在深拷贝中,源对象和副本是完全独立的。
形式化地,如果两个对象 o1 和 o2 是浅拷贝,那么:
- 它们不是同一个对象(
o1 !== o2)。 o1和o2的属性具有相同的名称且顺序相同。- 它们的属性值相等。
- 它们的原型链相等。
参见结构等价的定义。
所有属性都是原始值的对象的副本同时符合深拷贝和浅拷贝的定义。然而,讨论这种副本的深度并无意义,因为它没有嵌套属性,而我们通常在修改嵌套属性的上下文中讨论深拷贝。
对于浅拷贝,只有顶层属性被复制,而不是嵌套对象的值。因此:
- 对副本的顶层属性的重新赋值不会影响源对象。
- 对副本的嵌套对象属性的重新赋值会影响源对象。
在 JavaScript 中,所有标准内置对象复制操作(扩展语法、Array.prototype.concat()、Array.prototype.slice()、Array.from() 和 Object.assign())都创建浅拷贝,而不是深拷贝。
考虑以下示例,其中创建了一个 ingredientsList 数组对象,然后通过复制该 ingredientsList 对象创建了一个 ingredientsListCopy 对象。
1 | const ingredientsList = ["面条", { list: ["鸡蛋", "面粉", "水"] }]; |
对嵌套属性的重新赋值将在两个对象中可见。
1 | ingredientsListCopy[1].list = ["粘米粉", "水"]; |
对顶层属性的重新赋值(在这种情况下是 0 索引)只会在更改的对象中可见。
1 | ingredientsListCopy[0] = "米线"; |
11. 以下说法错误的是
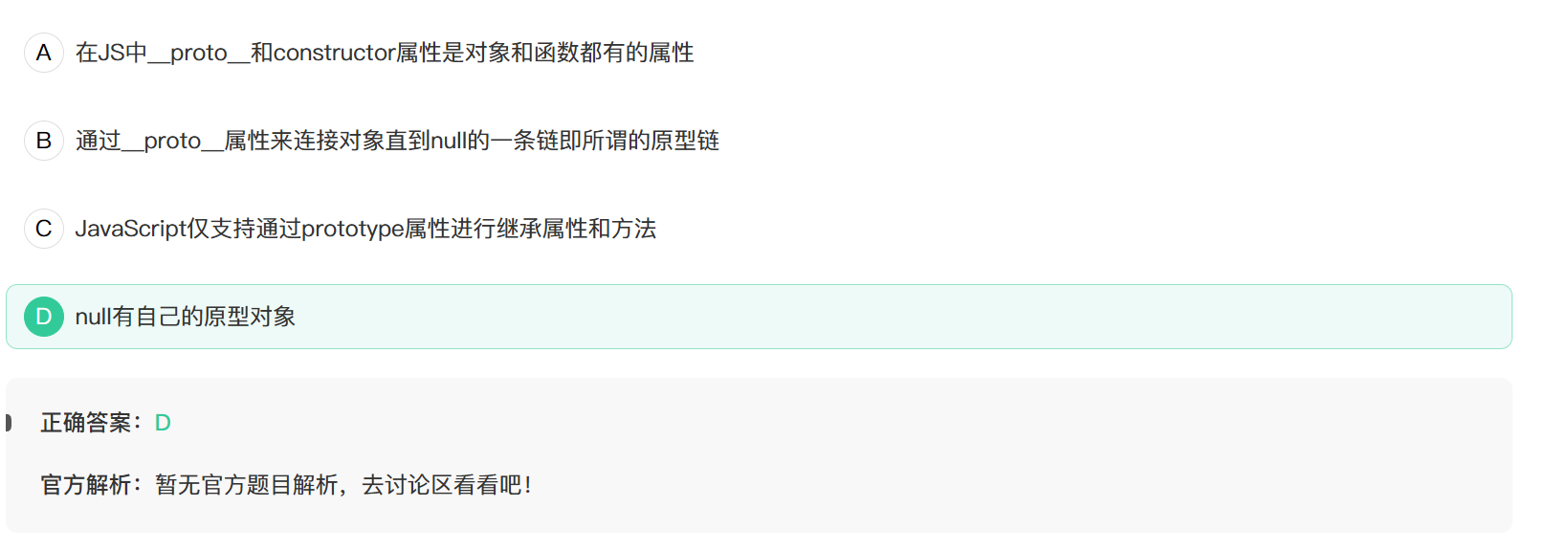
原型链
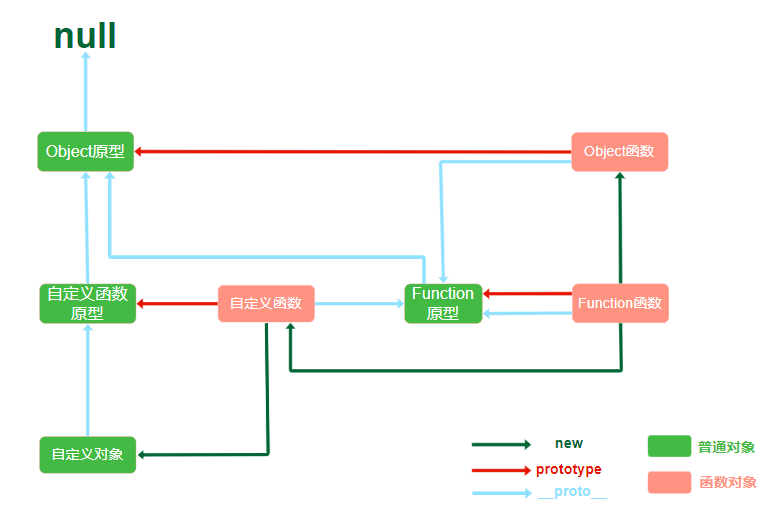
A. 函数也是对象,它有Function构造函数new出来.每一个对象都由其构造函数new出来,对象本身不一定有constructor属性,但是沿着原型链找,在其隐式原型__proto__上一定有constructor属性.A正确
B. 如上图,正确
C. 通过ES6的class语法使用extends继承的本质还是设置prototype,只是语法糖.
D. null是原型链的终点.null没有属性.
本题选错误的,选D
12. 以下说法正确的是

WebAPI
Ducoment.readyState属性描述了document 的加载状态。
当该属性值发生变化时,会在document 对象上触发 readystatechange 事件。
值
一个文档的readyState可以是以下之一:
loading(正在加载):document仍在加载。interactive(可交互): 文档已被解析,正在加载状态结束,但是诸如图像,样式表和框架之类的子资源仍在加载。compelete(完成): 文档和所有子资源已完成加载.表示表示load状态的事件即将被触发。
Document.readystatechange
当文档的 readyState 属性发生改变时,会触发 readystatechange 事件。
| 是否冒泡 | 否 |
|---|---|
| 是否可取消 | 否 |
| 接口 | Event |
| Event handler属性 | onreadystatechange |
这道题题目描述有问题,A选项中的”document已经load“应该指的并不是window上的load事件,而是说document的loading状态结束,已经解析完成.
B. 会触发两次,loading->reactive,reactive->complete
C. 这里指的应该是window的load事件.
load事件在整个页面及所有依赖资源如样式表和图片都已完成加载时触发.它与 DOMContentLoaded 不同,后者只要页面 DOM 加载完成就触发,无需等待依赖资源的加载。
该事件不可取消,也不会冒泡。
备注: 所有以
load命名的事件都不会传递到Window上,即使bubbles初始化为true。要在window上捕获load事件,相关的load事件必须直接绑定到window上。备注: 当主文档加载完成时,
load事件将在window上触发,但其有两个被修改的属性:target为document,以及path为undefined。这是由遗留的一致性问题导致的。
D. unload事件已经被废弃或不推荐使用.
当文档或一个子资源正在被卸载时,触发 unload 事件。
它在下面两个事件后被触发:
- beforeunload (可取消默认行为的事件)
- pagehide
文档处于以下状态:
- 所有资源仍存在 (图片,iframe 等.)
- 对于终端用户所有资源均不可见
- 界面交互无效 (
window.open,alert,confirm等.) - 错误不会停止卸载文档的过程
请注意unload事件也遵循文档树:父 iframe 会在子 iframe 卸载前卸载.
13. 以下函数打印结果为
1 | var User = { |
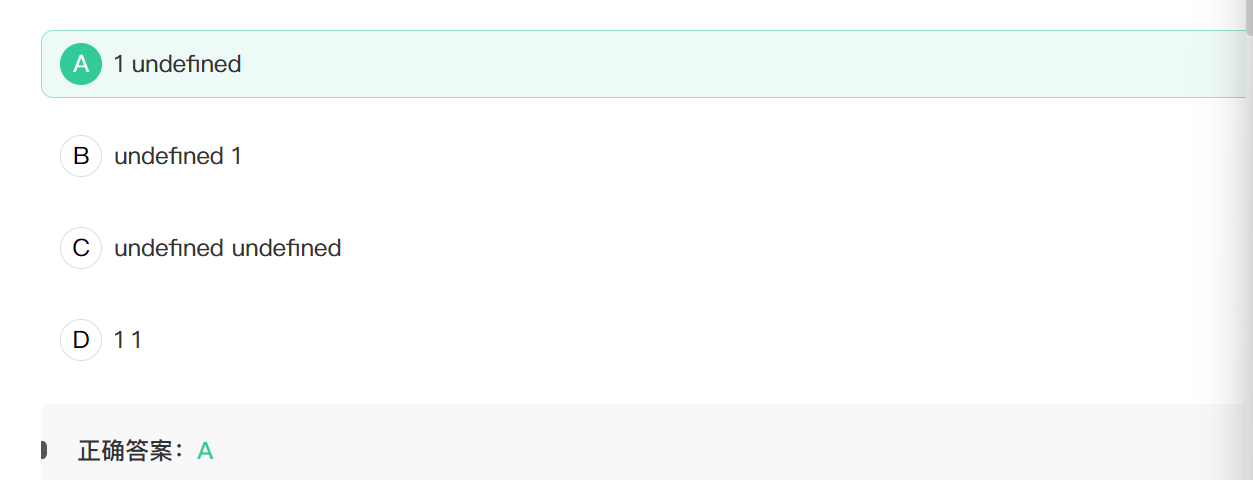
this指向
this指向调用者
第一个打印,调用者是User,所以this指向User,输出1.
第二个打印,调用者是window,this指向window,window上没有getCount()方法,所以返回undefined
14. var a = 1 + (1 > 2)?1:2; a=?
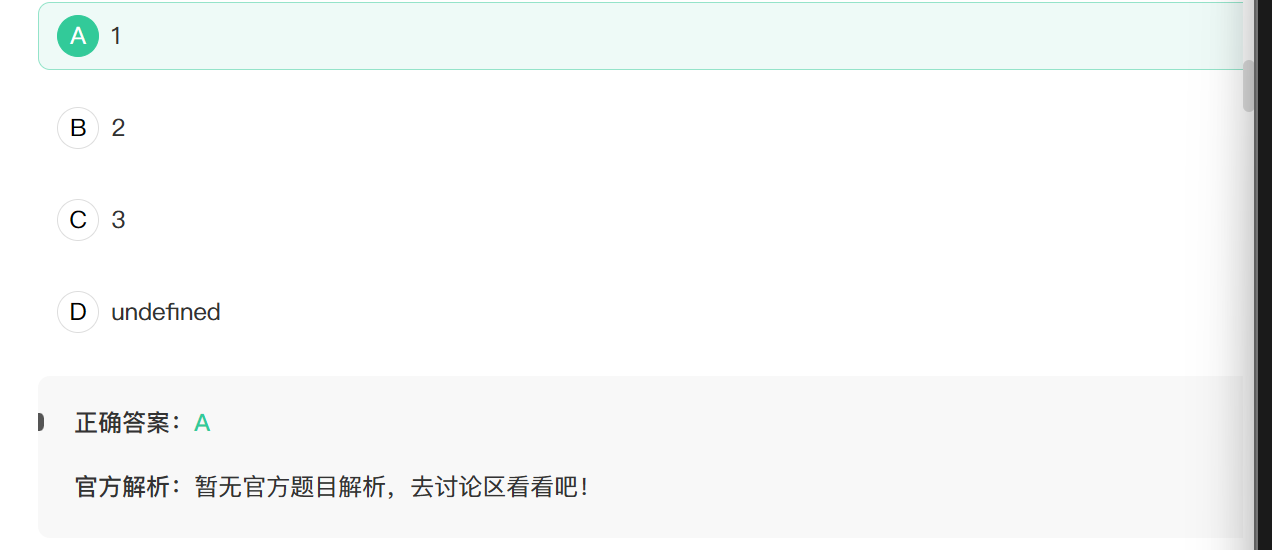
+加法运算法的优先级高于?:条件三元运算符
()小括号优先
首先计算小括号,这是一个逻辑判断式,结果为false,然后执行加法运算.加法运算是两种不同运算的重载:
- 数字加法
- 字符串连接
它首先将两个操作数强制转换为基本类型.然后,检查两个操作数的类型:
- 如果有一方是字符串,另一方则会被转换为字符串,并且将他们连接起来
- 如果双方都是
BigInt,则执行BigInt加法.如果一方是BigInt而另一方不是,则会抛出TypeError - 否则,双方都会被转换为数字,执行数字加法.
所以这里将false转换为数字,是数字0.三元运算符左边是1,是一个真值,所以取1.
15. var arr=["a","b","c","d"];arr.splice(2,1"e");arr=?
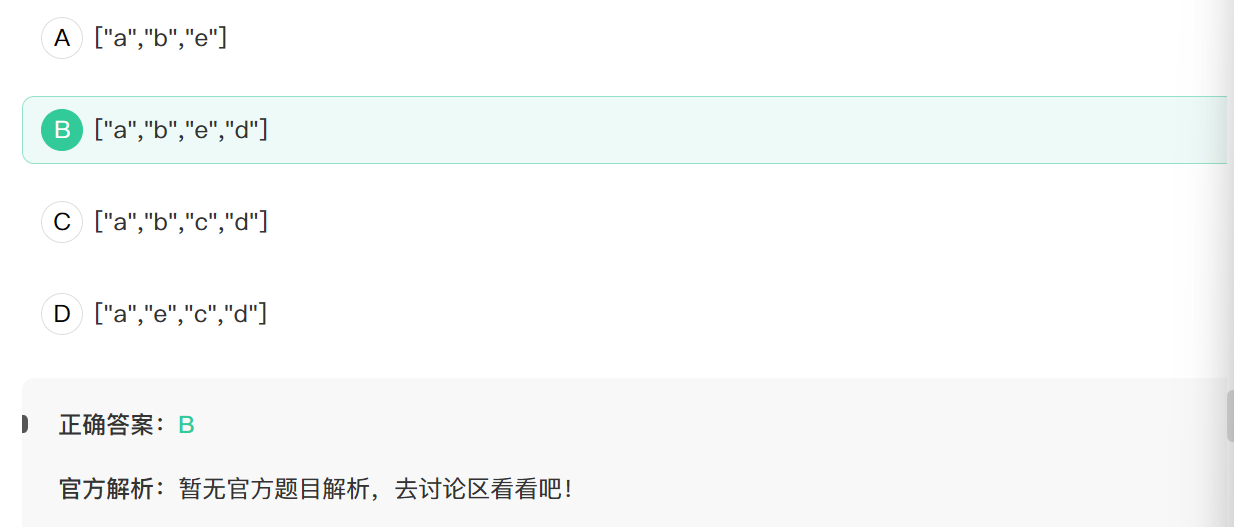
数组API
Array.prototype.splice(start,length,...alter)表示从下标start的位置删除length个元素,再新插入...alter这些元素.
所以这里在下标为2的位置删除1个,然后插入”e”,故最终结果为B
16. var a = 3; var b = 4; a = a ^ b; b = b ^ a;b=?
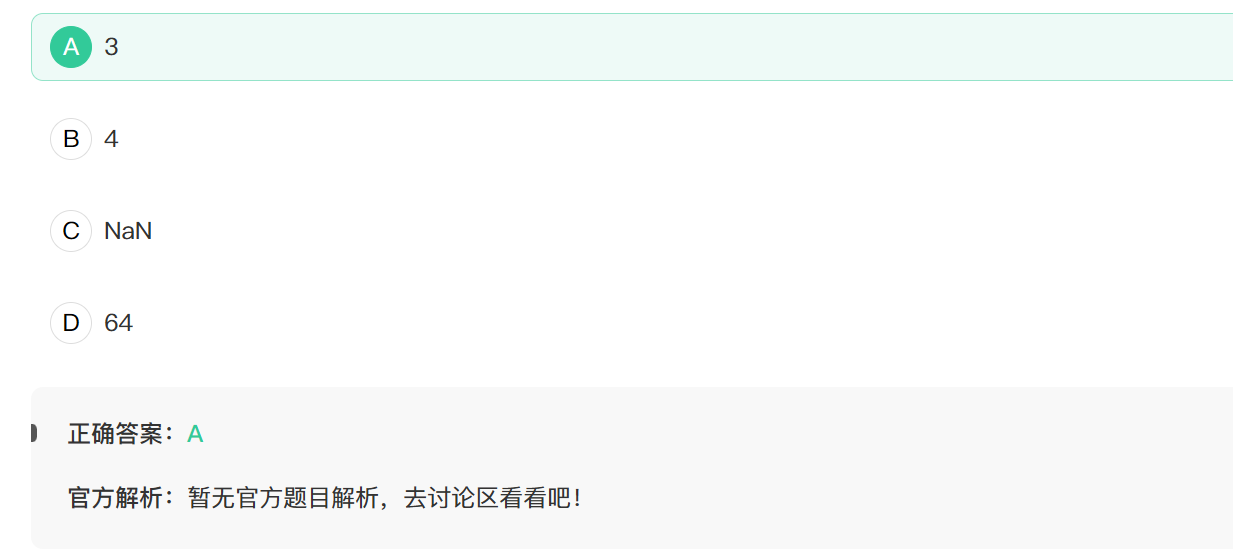
按位异或
首先把a与b按位异或的值赋给a,得到3,然后,再把b与a按位异或的值赋给b,还是3.
17. 以下关于变量提升的说法错误的是
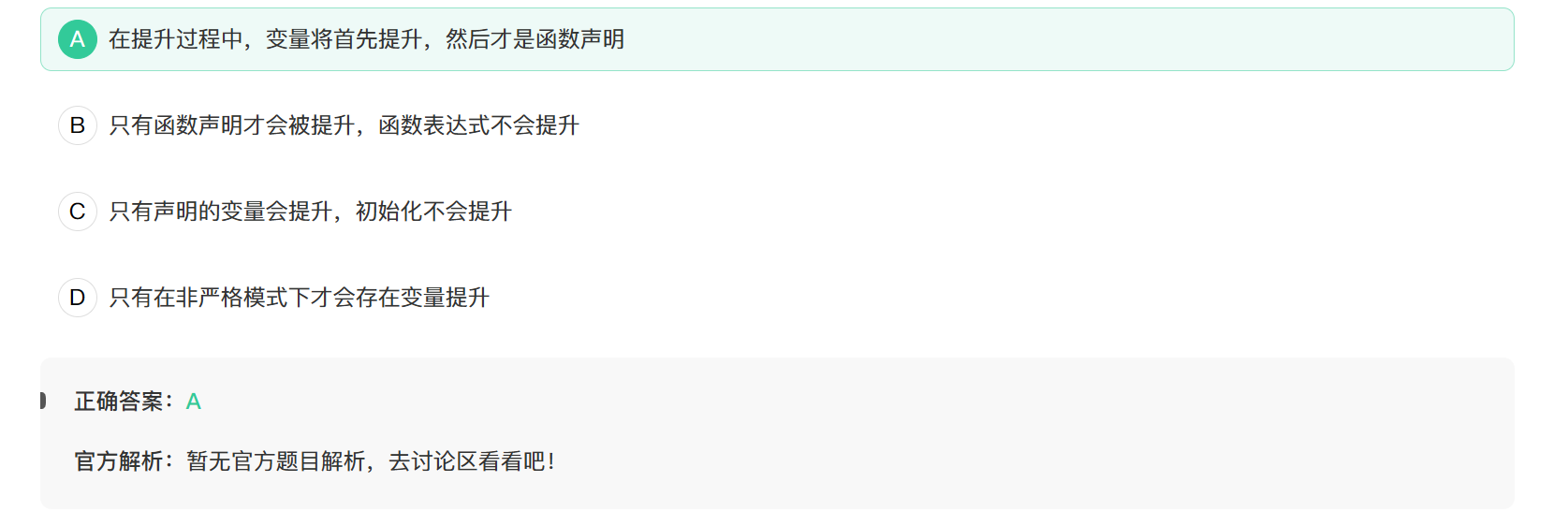
提升并不是
ECMA的官方说法,所以应该尽量避免使用此说法.
A 选项错误:
变量提升和函数提升是两个独立的过程,但函数声明会被提升到变量提升之上,所以顺序应该是先函数声明提升,再变量提升,而不是“变量先提升,然后才是函数声明”。
B 选项正确:
只有函数声明(function declaration)会被提升,而函数表达式(function expression)不会被提升。例如:
1 | console.log(fn); // undefined |
这里 fn 变量被提升,但它的初始化(赋值函数表达式)不会被提升,所以 fn 在 console.log 处是 undefined。
C 选项正确:
变量声明 (var x;) 会被提升,但初始化 (x = 10;) 不会提升。例如:
1 | console.log(a); // undefined |
这里 a 被提升,但 a = 10 不会被提升。
D 选项正确:
变量提升是 var 关键字的特性,在严格模式 ('use strict') 下依然存在,但严格模式会禁止使用未声明的变量,这可能会让人误以为变量提升不存在。例如:
1 | ; |
这里 a 从未声明,所以直接使用会报错,但如果使用 var a; 声明,变量仍然会被提升。
18. 下列哪项数据类型属于JavaScript的引用数据类型
19. 以下输出结果哪项是错误的.
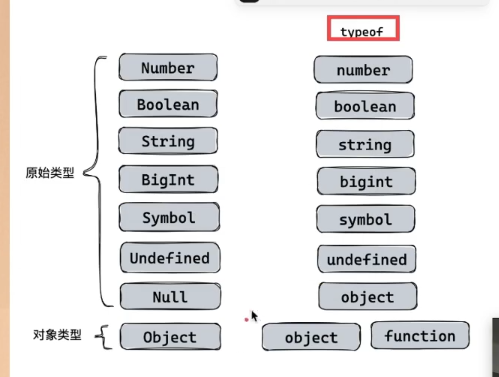
typeof,相等判断
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Data_structures
相等(==)运算符检查其两个操作数是否相等,返回一个布尔值结果。与严格相等运算符不同,它会尝试转换不同类型的操作数,并进行比较。
相等运算符(== 和 !=)提供非严格相等语义。这可以大致总结如下:
- 如果操作数具有相同的类型,则按如下方式进行比较:
- 对象(Object): 仅当两个操作数引用同一个对象是返回
true. - 字符串(String): 仅当两个操作数具有相同的字符且顺序相同时返回
true - 数字(Number): 如果两个操作数相同,则返回
true.+0和-0被视为相同的值.如果任何一个操作数是NaN,返回false;NaN永远不等于NaN - 布尔值(Boolean): 仅当操作数都为
true或都为false时返回true - 大整形(BigInt): 仅当两个操作数引用相同的符号时返回
true
- 对象(Object): 仅当两个操作数引用同一个对象是返回
- 如果其中一个操作数为
null或undefined,另一个操作数也必须为null或undefined以返回true。否则返回false。 - 如果其中一个操作数是对象,另一个是原始值,则将对象转换为原始值。
- 在这一步,两个操作数都被转换为原始值(字符串、数字、布尔值、符号和大整型中的一个)。剩余的转换将分情况完成。
宽松相等是对称的:A == B 对于 A 和 B 的任何值总是具有与 B == A 相同的语义(应用转换的顺序除外)。
该运算符与严格相等(===)运算符之间最显著的区别是,严格相等运算符不尝试类型转换。相反,严格相等运算符总是认为不同类型的操作数是不同的。严格相等运算符本质上只执行第 1 步,然后对所有其他情况返回 false。
上面的算法有一个“故意违反”:如果其中一个操作数是 document.all,则它被视为 undefined。这意味着 document.all == null 是 true,但 document.all === undefined && document.all === null 是 false。
20.
1 | <ul id="ulid"> |
可以将页面中的”AAA”和”BBB”文字设置为红色(#ff0000)的样式是:

A,B选项中用空格隔开选择器表示后代选择器,没问题,CD中的ul.item或li.item没有用空格隔开,表示同时满足,比如C,选择的是class="item"并且标签名为ul的标签.
21. 下面CSS属性中可以继承父元素的有()
一般和文字相关的属性是可以继承的.
22.下列是原生JavaScript的方法有()
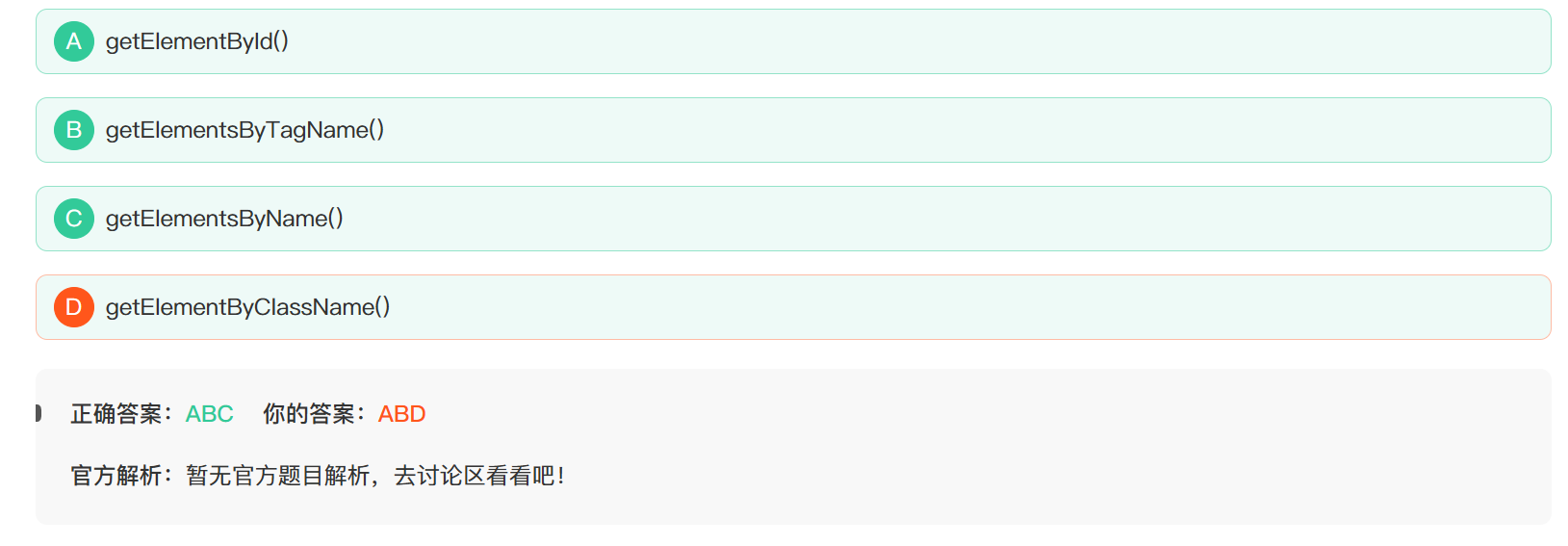
D选项少了一个s
23. 以下哪些会出现跨域请求
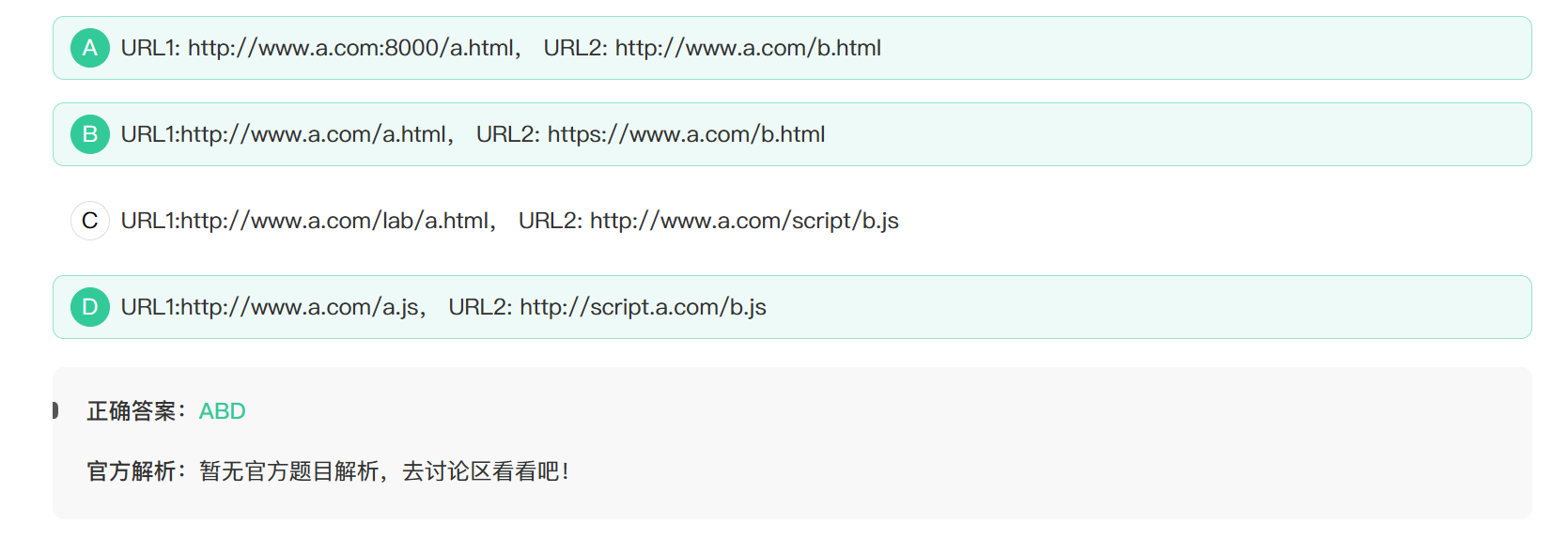
跨域请求
跨域请求是由于浏览器的同源策略而发生的问题.
这三者只要有一个不同,就是跨域.其中域名哪怕是不同的子域名也会跨域.但是同一域名下不同的路径之间不会跨域.
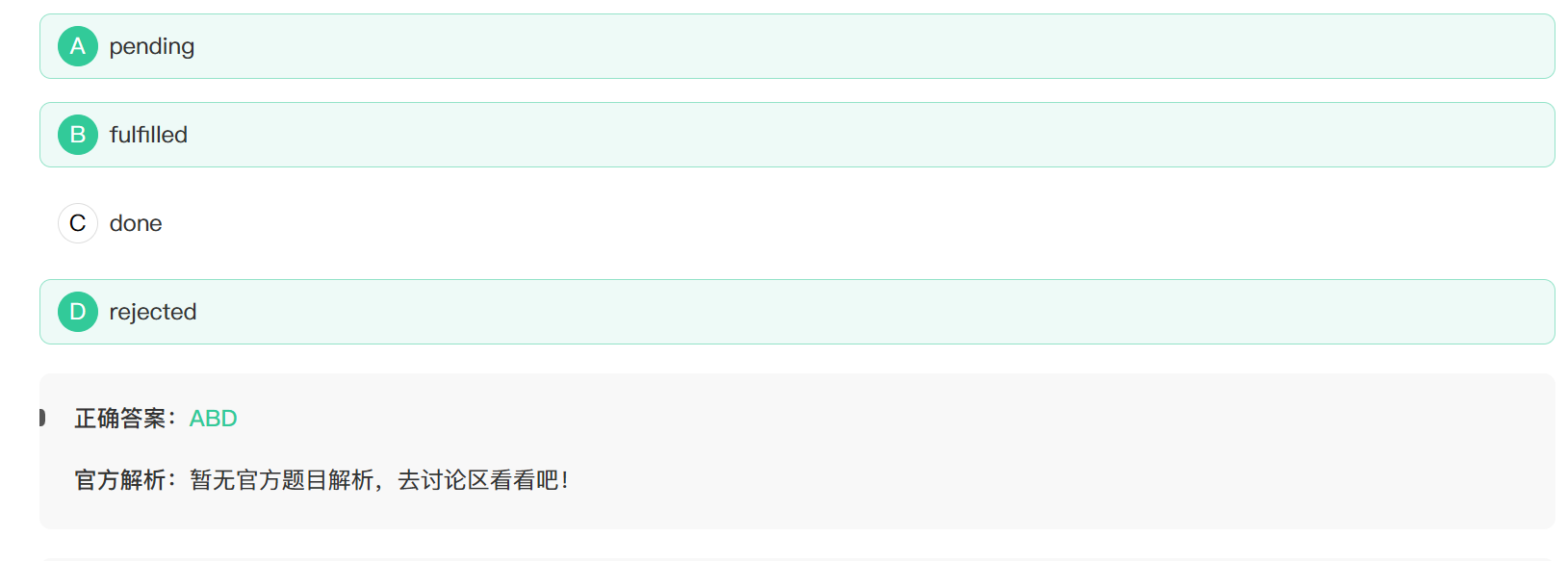
24. promise在生命周期的三种状态有?
25.问题描述:
用JavaScript实现把一个合数用质因数相乘的形式表示出来,并按要求格式输出。例如: 100=2*2*5*5
输入描述: 输入一个整数n
输出描述: 查找并输出整数n的质因数
输入样例: 100
输出样例: 100=2*2*5*5
1 | function primeFactorization(n) { |
26. 问题描述
输入描述: 字符串
输出描述: 反转后字符串
输入样例: lenovo
输出样例: lonove
1 | function reverseVowels (s) { |
27. 运行以下程序,打印的结果是
1 | function A() {} |
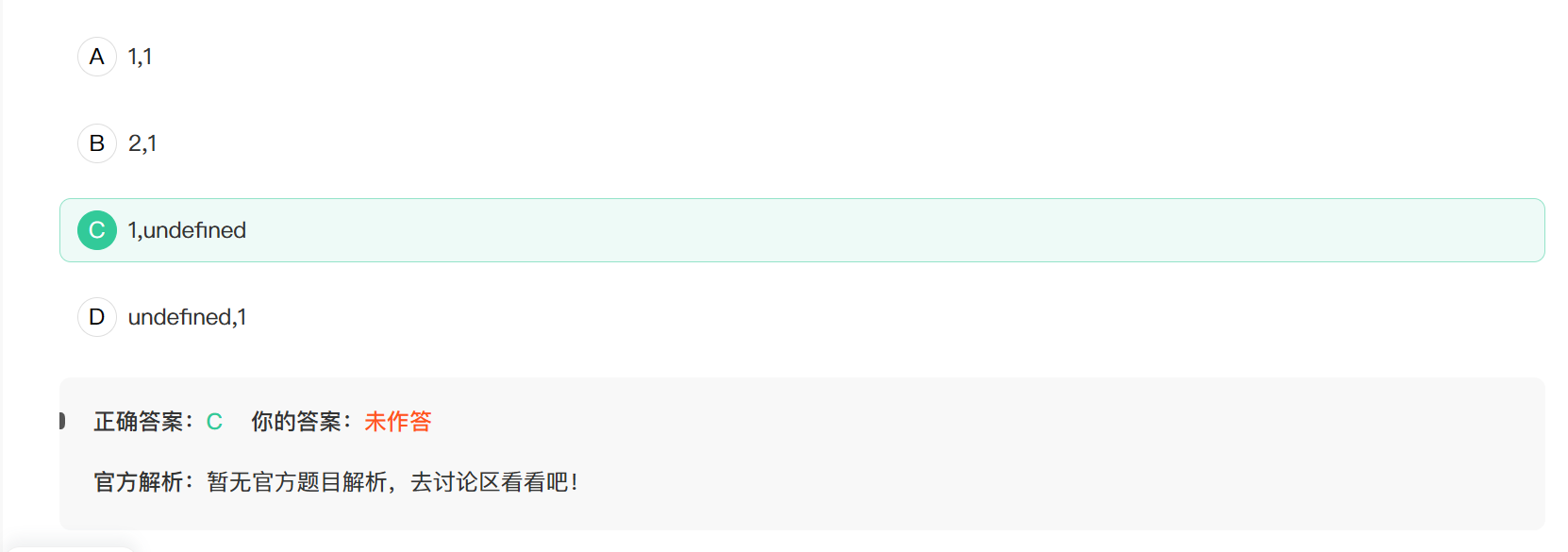
原型链
A没有往当前实例添加x属性,所以沿着原型链查找,找到1
B由于构造函数中,把传入参数作为x的值,但是实例化的时候却没有传入具体的值,所以是undefined
 微信
微信 支付宝
支付宝
