OPPO24秋
考情分析
逐题解析
1. 执行以下程序,对于①②式能否在a标签上实现效果,下列说法正确的是
1 |
|

CSS属性值的计算过程
正确答案: D
官方解析:这道题目考察了CSS样式继承的特性。D选项正确,因为字体大小(
font-size)属性可以被子元素继承,而文本装饰(text-decoration)属性则不能。具体分析:
font-size属性是可继承属性,div标签上设置的font-size:12px会被其子元素a标签继承,因此②式可以在a标签上实现效果。
text-decoration属性不能被继承,在div标签上设置text-decoration:none不会影响到其内部的a标签,所以①式不能在a标签上实现效果。如果要去掉a标签的下划线,需要直接在a标签上设置该属性。其他选项错误原因:
A错误:因为text-decoration不能继承,所以不可能两式都能实现效果
B错误:font-size是可以继承的,所以不可能两式都不能实现效果
C错误:与实际情况相反,①式不能实现效果而②式可以这也提醒我们在CSS开发中要注意区分哪些属性是可继承的,哪些是不可继承的,这对于正确实现样式效果很重要。
这道题考察我们CSS属性值的计算过程,分为以下四步:
确定声明值:没有冲突的样式属性直接应用
层叠:解决冲突,具体分为以下三步
比较重要性: 带有
!important的默认样式 > 带有!important的作者样式 > 作者样式 > 默认样式比较特定性: 重要性相同的情况下,比较CSS选择器的特定性.内联样式特定性最高*,除此之外,特定性用三个分量来表示
(a,b,c)- a表示id选择器的数量
- b表示类选择器,伪类选择器,属性选择器的数量
- c表示元素选择器,伪元素选择器的数量\
依次比较三个分量,大的特定性更高,优先使用.
比较在源码中的次序: 在重要性和特定性都相同的情况下,在源码中靠后的代码会覆盖靠前的代码,有更高的样式优先级.
继承:前两个步骤完成后,还没有值,并且该属性是可继承的,使用继承值
使用默认值: 前三个步骤完成后,还没有值的属性,使用默认值.
2. 下列选项的属性,在块级元素中不会生效的是()

块级格式化上下文和行级格式化上下文
正确答案: B
vertical-align属性主要作用于行内元素和单元格(table-cell)元素,在块级元素中不会生效。这是因为块级元素默认会占据其父容器的整行,不存在垂直对齐的概念。
分析其他选项:
line-height(行高)在块级元素中是有效的,用于控制文本行之间的间距。
text-align(文本对齐)在块级元素中可以控制其内部内容的水平对齐方式。
text-shadow(文字阴影)同样适用于块级元素中的文本。补充说明:
如果要在块级元素中实现垂直对齐的效果,通常需要使用其他CSS属性组合,比如:
- 使用padding或margin
- 使用flex布局
- 使用grid布局
- 设置具体的height和line-height值这也是为什么在实际开发中,要根据具体场景选择合适的布局方式和CSS属性组合。
3. 执行以下程序,当给main盒子添加overflow:hidden;则变化情况为()
1 |
|

视觉格式化模型:常规流,浮动,定位,块级格式化上下文,行级格式化上下文.
正确答案: B
官方解析:这道题主要考察CSS中浮动元素和overflow属性对布局的影响。
在未添加overflow:hidden之前,由于sideBar设置了float:left,会造成浮动,使其脱离文档流。此时main盒子会无视浮动元素的存在,从最左边开始布局,所以main盒子会紧贴在sideBar左边。
当给main盒子添加overflow:hidden后,会触发BFC(块级格式化上下文)。BFC的一个重要特性是可以阻止元素被浮动元素覆盖,使得main盒子会根据浮动元素的位置进行布局,因此main盒子会紧贴在sideBar的右边。
所以选项B是正确的。
分析其他选项:
A错误:描述与实际情况相反。添加overflow:hidden前main在左,添加后在右。C错误:main盒子的位置会因overflow:hidden的添加而改变,不会保持不变。
D错误:开始时main盒子并不是紧贴在sideBar右边,而是在最左侧,与sideBar重叠。
这个现象展示了CSS中BFC的重要作用,它不仅可以清除浮动,还能改变元素的布局规则,是页面布局中的重要机制。
在没有添加overflow:hidden时,在常规流布局中,浮动元素后的块盒会直接无视浮动元素,好像浮动元素完全不存在一样.所以布局如下:

添加overflow:hidden后,main创建一个BFC,创建BFC的元素有以下三个主要特点:
- 创建BFC的元素,它的自动高度需要计算浮动元素.
- 创建BFC的元素,它的边框盒不会与浮动元素重叠.
- 创建BFC的元素,不会和它的子元素进行外边距合并(不同BFC中的元素的外边距不能合并);
所以添加后,main盒子不能无视sideBar,只能避开它,如下图

4. 此代码的运行结果为
1 | console.log(0 && 1, 0 || 1, 1 && 3, 1 ||3); |

真值,假值
正确答案: A
官方解析:这道题目考察了JavaScript中逻辑运算符(&&和||)的运算规则。让我们逐个分析每个表达式:
0 && 1 结果为 0:
因为&&运算符遇到假值就会立即返回,0是假值,所以直接返回0。0 || 1 结果为 1:
因为||运算符遇到假值会继续往后找真值,0是假值所以继续判断1,1是真值所以返回1。1 && 3 结果为 3:
因为&&运算符在左侧为真值时会返回右侧操作数,1是真值所以返回3。1 || 3 结果为 1:
因为||运算符遇到真值就会立即返回,1是真值所以直接返回1。所以最终输出结果是: 0 1 3 1
分析其他选项:
B选项(0 1 3 3)错误:最后一个表达式1 || 3应该返回1而不是3
C选项(0 1 1 3)错误:第三个表达式1 && 3应该返回3而不是1
D选项(0 0 1 3)错误:第二个表达式0 || 1应该返回1而不是0因此A选项(0 1 3 1)是正确答案。
真值
在 JavaScript 中,真值是在布尔值上下文中,转换后的值为 true 的值。被定义为假值以外的任何值都为真值。(即所有除 false、0、-0、0n、""、null、undefined 和 NaN 以外的皆为真值)。
JavaScript 在布尔值上下文中使用强制类型转换。
JavaScript 中的真值示例如下(这些值会被强制转换为 true,因此 if 后的代码段将被执行)
如果第一个对象为真值,则逻辑与运算返回第二个操作数。
假值
假值(falsy,有时写为 falsey)是在布尔上下文中认定为 false 的值。
JavaScript 在需要用到布尔类型值的上下文中使用类型转换将值转换为布尔值,例如条件语句和循环语句。
下列表格提供了 JavaScript 的所有假值。
| 值 | 类型 | 描述 |
|---|---|---|
| null | Null | 关键词 null — 任何值的缺失 |
| undefined | Undefined | undefined — 原始类型值 |
false |
Boolean | 关键字 false。 |
| NaN | Number | NaN — 不是一个数字 |
0 |
Number | Number 零,也包括 0.0、0x0 等。 |
-0 |
Number | Number 负的零,也包括 -0.0、-0x0 等。 |
0n |
BigInt | BigInt 零,也包括 0x0n 等。需要注意没有 BigInt 负的零 —— 0n 的相反数还是 0n。 |
"" |
String | 空字符串值,也包括 '' 和 ````。 |
document.all |
Object | 唯一具有假值的 JavaScript 对象是内置的 document.all。 |
5. 此代码的运行结果为
1 | var arr = [1, 2, 5, 7, 8]; |
双重for循环遍历
正确答案: D
官方解析:这道题目考察了双重循环遍历数组寻找目标和的逻辑。
代码中使用两层for循环遍历数组arr=[1,2,5,7,8],目的是找出数组中两个元素之和等于12的下标组合。让我们分析执行过程:
当arr[i] + arr[j] = 12时:
- 当i=2, j=3时,arr[2]=5, arr[3]=7, 5+7=12,输出”2 3”
- 当i=3, j=2时,arr[3]=7, arr[2]=5, 7+5=12,输出”3 2”所以会输出两组结果:
2 3
3 2因此D选项是正确答案。
分析其他选项:
A错误:5 7是数组元素值而不是下标
B错误:只列出了一组结果2 3,没有包含3 2
C错误:同样是列出了元素值而不是下标这个题目的关键是要理解:
\1. 输出的是满足条件的元素下标而不是元素值
\2. 由于是双重循环,所以会出现两组互换位置的结果
\3. 需要完整列出所有满足条件的组合
6. 请问以下JS代码的输出结果是()
1 | const p1 = Promise.resolve(117); |

Promise静态方法
正确答案: A
这道题考察了
Promise.resolve()的行为特性和Promise对象的比较。A选项”true、true、false“是正确答案。让我们逐个分析:
p1 == p2结果为true:
当使用Promise.resolve()处理一个Promise对象时,它会直接返回这个Promise对象,而不会创建新的Promise。所以p2实际上就是p1,它们是同一个对象引用。
p1 === p2结果为true:
由于p1和p2是完全相同的对象引用,使用严格相等运算符===比较也返回true。
p1 === p3结果为false:
虽然p1和p3都是通过Promise.resolve(117)创建的,但它们是两个独立的Promise对象。每次调用Promise.resolve()都会创建一个新的Promise实例(除非参数是Promise对象)。其他选项错误原因:
B选项”true、false、true”错误:因为p1和p2是同一个对象引用,严格相等的比较结果应该是true。
C选项”false、false、true”错误:p1和p2的比较结果都应该是true。
D选项”false、false、false”错误:完全相反,p1和p2的比较结果都应该是true。这个题目很好地体现了
Promise.resolve()的一个重要特性:当传入Promise对象时会返回该Promise对象本身,而传入非Promise值时则会创建新的Promise实例。
7. 请问以下JS代码的最终输出结果是()
1 | const obj = { |

代理Proxy, this指向
正确答案: B
代码中涉及了普通对象调用和
Proxy代理对象调用函数时的this指向问题。选项B是正确的,让我们逐行分析代码执行过程:
- 首先创建了一个包含
flag属性和func方法的对象obj- 然后用
Proxy创建了obj的代理对象p,这里没有设置任何handler拦截器- 代码依次执行了
p.func()和obj.func()执行
p.func()时:
- 第一个console.log(this)输出Proxy对象:Proxy {flag: 'Jhon', func: ƒ}
- 第二个console.log(this.flag)输出"Jhon"执行
obj.func()时:
- 第一个console.log(this)输出原始对象:{flag: 'Jhon', func: ƒ}
- 第二个console.log(this.flag)输出"Jhon"分析其他选项错误原因:
A错误:第二个输出应该是”Jhon”而不是undefined
C错误:obj.func()调用时this指向原对象而不是Proxy对象
D错误:p.func()调用时this指向Proxy对象而不是原始对象关键点在于:使用Proxy代理后,调用代理对象的方法时this指向代理对象本身,而调用原始对象的方法时this指向原始对象。但由于这里的代理对象完全透明(没有任何拦截器),所以对flag属性的访问结果是一样的。
代理(Proxy)
Proxy对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找,赋值,枚举,函数调用等).
术语
<dfn>handler</dfn>包含捕捉器(trap)的占位符对象,可译为处理器对象。
-
提供属性访问的方法。这类似于操作系统中捕获器的概念。
-
被 Proxy 代理虚拟化的对象。它常被作为代理的存储后端。根据目标验证关于对象不可扩展性或不可配置属性的不变量(保持不变的语义)。
语法
1 | const p = new Proxy(target, handler); |
参数:
target:要使用Proxy包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理)
handler:一个通常以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理p的行为.
方法
-
创建一个可撤销的
Proxy对象。
handler对象的方法
handler对象是一个容纳一批特定属性的占位符对象.它包含有Proxy的各个捕获器(trap);
所有的捕捉器都是可选的.如果没有定义某个捕捉器,那么就会保留源对象的默认行为.
-
Object.getPrototypeOf方法的捕捉器。 -
Object.setPrototypeOf方法的捕捉器。 -
Object.isExtensible方法的捕捉器。 -
Object.preventExtensions方法的捕捉器。 handler.getOwnPropertyDescriptor()Object.getOwnPropertyDescriptor方法的捕捉器。-
Object.defineProperty方法的捕捉器。 -
in操作符的捕捉器。 -
属性读取操作的捕捉器。
-
属性设置操作的捕捉器。
-
delete操作符的捕捉器。 -
Object.getOwnPropertyNames方法和Object.getOwnPropertySymbols方法的捕捉器。 -
函数调用操作的捕捉器。
-
new操作符的捕捉器。
一些不标准的捕捉器已经被废弃并且移除了。
8. 现已知信噪比为30dB,信道带宽为8kHz,则信道容量大约为()

香农公式
正确答案: D

9. 如果一个磁盘块的大小是100字符,一文件中的第0到第99字符位于第5个磁盘块上,那么第280到300字符位于第几号磁盘块上?

正确答案:B
考查操作系统中的文件。一个磁盘块的大小是100字符,一文件中的第0到99的字符位于第5个磁盘块上,那么第280到300的字符位于5+200/100=7号磁盘块上
知识点:操作系统
10. 请问在严格模式和非严格模式下,下列JS代码的最终输出的结果分别是()
1 | function func(a) { |
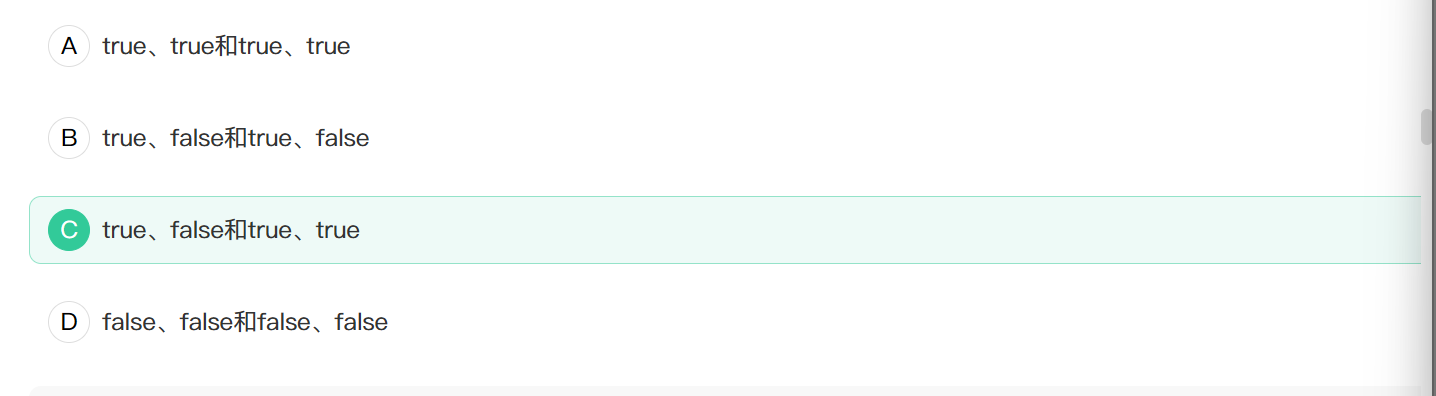
严格模式和非严格模式
正确答案: C
官方解析:这道题目考察了JavaScript中严格模式和非严格模式下参数与arguments对象的关系。
在非严格模式下,函数的参数和arguments对象是相互关联的。当修改参数a的值时,arguments[0]也会跟着改变,反之亦然。因此第一次输出true(1 \=== 1),第二次也输出true(2 === 2)。
而在严格模式下,函数的参数和arguments对象是互相独立的。修改参数a的值不会影响arguments[0]。所以第一次输出true(1 === 1),但第二次输出false(2 !== 1),因为a变成了2,而arguments[0]依然是1。
分析其他选项:
A错误:认为严格和非严格模式下表现一致,都是true,没有考虑到严格模式下参数与arguments的独立性。B错误:虽然严格模式下的结果(true、false)是对的,但非严格模式下的结果(true、false)是错的。
D错误:完全错误的理解,两种模式下第一次比较必定是true,因为此时a和arguments[0]都是初始传入的值1。
因此C选项”true、false和true、true”正确地反映了严格模式和非严格模式下的不同行为。
11. UDP属于尽力而为的不可靠传输,使用UDP传输的数据,其可靠性要在那一层保证?

计算机网络
正确答案: D
官方解析:UDP是一个无连接的、不可靠的传输层协议,如果用户采用UDP传输数据,必须在传输层的上层提供可靠性保证的工作,表示层只负责转化数据的表现形式,因此只能是应用层保证可靠性,选D。
知识点:网络基础
12. 主机A与主机B建立了一条TCP协议,采用的是GBN重传方式.假如发送窗口是3,在时刻t,接收方期待的下一个有序分组的序号是k,请问这个时候发送方窗口内的报文序号可能是多少(假设接受主机不会对报文重新排序)

可靠传输的方法
正确答案: B
官方解析:首先我们需要抓住关键—GBN协议,然后反应出GBN协议几个特点:发送方拥有一个窗口,长度为N=3;接收方无窗口,只接收希望接受序号的报文,对于失序到达的报文段采取的方式是直接丢弃;在重传的时候,将会重传当前发送方窗口中所有未被确认的报文段。在t时刻,接收方起到收到的下一个分组序号为k,说明接收方已经正确接受了k之前的所有分组,对于发送方而言,我们考虑两种最极端的情况:
第一种情况:假设之前所有的报文都正确传输,没有任何丢失的问题,那么在这种情况下,发送方正确接收了接收方对于小于k的所有报文的ACK确认,因此窗口将会不断向后移动,序号为k、k+1、k+2;
第二种情况:由已知条件我们可以得知序号为k-1的报文是发送方发送的最后一个报文,假设该报文虽然到达了接收方,但是接收方返回的ACK确认由于一些原因没有到达发送方,则窗口不会移动,在这种情况下我们再假设序号k-1位于窗口的最后一列,即如下图所示的所有序号报文都没有在发送方被确认,则得到了我们最坏的一种情况,k-3、k-2、k-1;综合上述两种情况,[k-3, k+2]区间内的都可能出现,因此选B。
13. Linux中,假设当前用户zhangsan所在目录为/home,则想要切换到zhangsan的家目录 /home/zhangsan 下,则下面命令不能实现的是?

Linux基础
正确答案: B
这道题目考察了Linux系统中切换目录的cd命令使用。B选项”cd /zhangsan”是错误的,因为这个路径指向的是根目录下的zhangsan目录,而不是/home/zhangsan目录。在当前位置(/home)要切换到用户zhangsan的家目录,这个路径是错误的。
分析其他选项:
A正确:cd /home/zhangsan 使用绝对路径,直接指向用户zhangsan的家目录
C正确:cd ../home/zhangsan 使用相对路径,先回到上级目录,再进入home/zhangsan
D正确:cd ~ 是切换到当前用户家目录的快捷命令,等同于cd $HOME补充说明:
\1. Linux中每个用户都有自己的家目录,通常位于/home/用户名下
\2. cd命令支持绝对路径(以/开头)和相对路径
\3. ~是一个特殊符号,代表当前用户的家目录
\4. 当前在/home目录下时,直接cd zhangsan也是可以进入/home/zhangsan的所以B选项的路径表示方式是错误的,不能实现切换到用户zhangsan的家目录的目的。
14. Linux中,执行以下命令的结果是()
1 | basename /etc/sysconfig/network |

Linux基础
正确答案: D
官方解析:basename命令用于去除路径中的目录部分,只返回文件名或最后一个路径组件。在这个例子中,对于路径”/etc/sysconfig/network”:
basename命令会返回路径中的最后一个组件,即”network”,所以D选项是正确答案。
分析其他选项:
A错误:”/etc”是完整路径的第一个目录组件,而basename只返回最后一个组件。B错误:”/etc/sysconfig/network”是完整的路径,而不是basename的结果。
C错误:”/etc/sysconfig”是路径的前两个目录组件,不是basename的返回结果。
补充说明:
- basename命令常用于shell脚本中,用来获取文件名,去除路径信息
- 如果想获取路径部分,应该使用dirname命令
- basename命令的基本语法是:basename [路径]
- 它会删除掉最后一个”/“及其之前的所有内容,只保留最后的文件名或目录名
15. 中缀表达式a*b+c/d-e的前缀表达式是()

数据结构与算法.树,栈
正确答案: A
给每一步运算都加上括号,按优先级把括号中的运算符移动到括号前.
16. 下面哪种进程调度算法可能导致低优先级进程饥饿:()
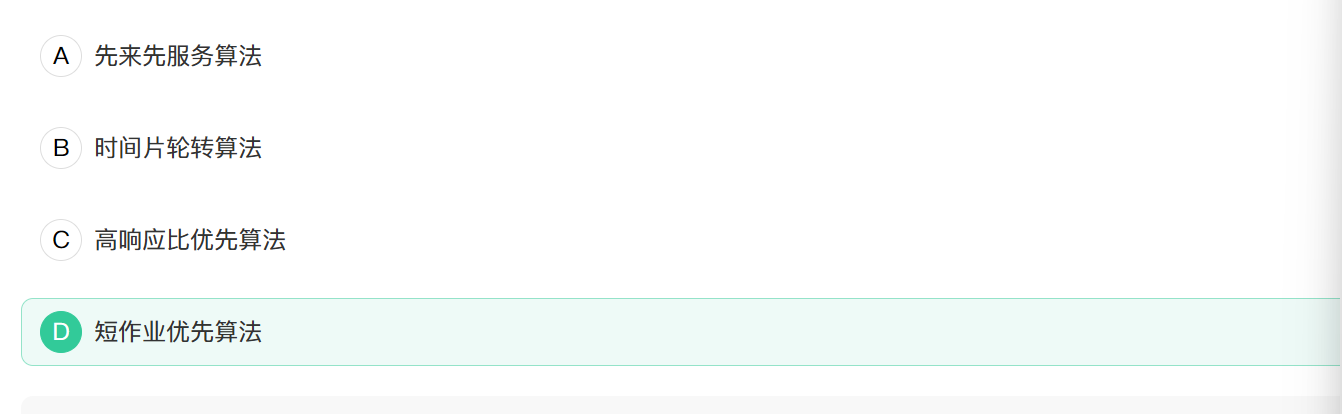
操作系统,进程管理
正确答案: D
短作业优先(SJF)调度算法可能会导致低优先级进程出现饥饿现象.因为SJF算法总是优先执行时间最短的进程运行,如果系统重不断有短进程到来,那么执行时间较长的进程可能会一直得不到处理机,从而发生”饥饿”现象.
A.先来先服务(FCFS)算法按照进程到达的先后顺序进行调度,只要进程到达就会被依次执行,不会饥饿.
B.时间片轮转(RR)算法让所有进程轮流执行,每个进程分配相同的时间片,所有进程都能得到公平对待,不会饥饿.
C.高响应比优先(HRRN)算法同时考虑进程等待时间和执行时间,响应比=(等待时间+要求服务时间)/要求服务时间.等待时间越长,优先级越高,可以避免饥饿.
17. 进度环
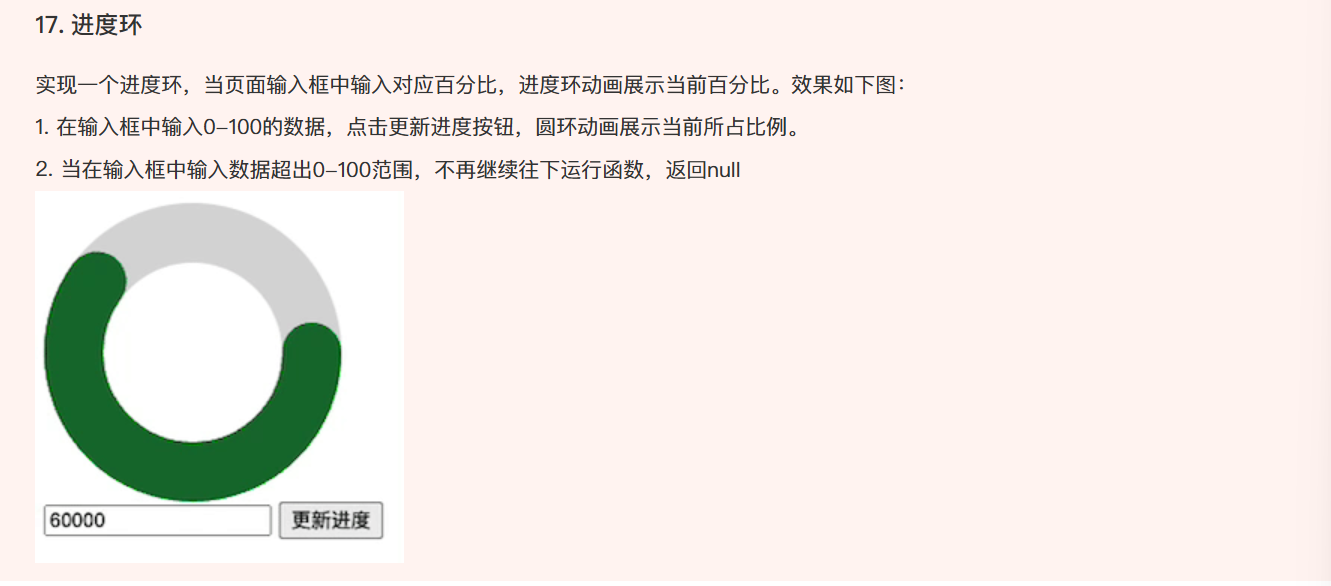
1 |
|
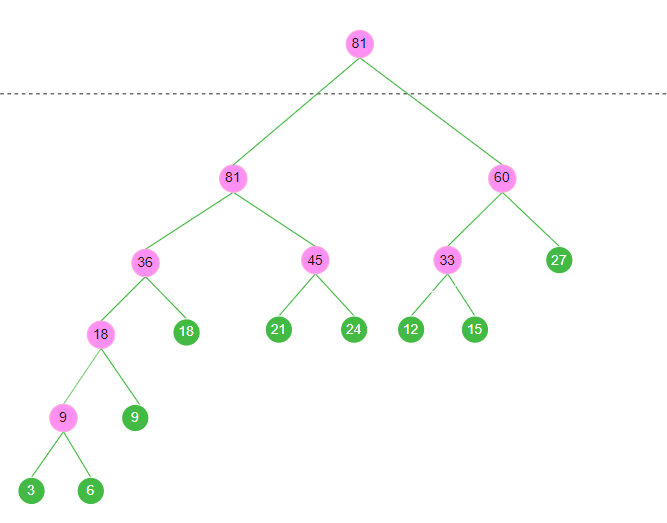
18. 若以{3, 6, 9, 12, 15, 18, 21, 24, 27}作为叶子结点的权值构造一棵哈夫曼树,则其带权路径长度是( )

正确答案: A
官方解析:构造哈夫曼树的过程是将权值最小的两个结点不断合并,形成新的结点,直到只剩一个根结点。让我们逐步计算:
\1. 首先对原始权值排序: 3,6,9,12,15,18,21,24,27
\2. 合并过程:
- 第1次: 3+6=9(新结点)
- 第2次: 9+9=18(新结点)
- 第3次: 12+15=27(新结点)
- 第4次: 18+18=36(新结点)
- 第5次: 21+24=45(新结点)
- 第6次: 27+27=54(新结点)
- 第7次: 36+45=81(新结点)
- 第8次: 54+81=135(根结点)\3. 计算带权路径长度(WPL):
- 3和6在第4层: (3+6)×4=36
- 9在第3层: 9×3=27
- 12和15在第3层: (12+15)×3=81
- 18在第3层: 18×3=54
- 21和24在第2层: (21+24)×2=90
- 27在第2层: 27×2=54
- 最后: 36+27+81+54+90+54=405因此带权路径长度为405,A选项正确。
其他选项分析:
B(406),C(508),D(510)都是错误的数值,可能是由于计算过程中的错误或使用了不同的合并顺序导致。在构造哈夫曼树时,始终选择最小的两个结点合并才能得到最优解,即最小的带权路径长度405。
19. 已知一个有序表(2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26),当二分查找值为15的元素时,若采取向上取整的方式取中间值,查找成功的比较次数为( )

二分法查找
正确答案: B
官方解析:让我们通过二分查找的过程来分析查找值15所需的比较次数。在向上取整的情况下:
第1次比较:
数组长度为13,中间位置 (13+1)/2=7(向上取整)
比较arr[7]=16 > 15,右边界更新为6第2次比较:
区间长度为6,中间位置 (6+1)/2=4(向上取整)
比较arr[4]=10 < 15,左边界更新为5第3次比较:
区间长度为2,中间位置 (2+1)/2=2(向上取整)
比较arr[6]=14 < 15,左边界更新为7第4次比较:
最后比较arr[7]=16 > 15,查找失败总共进行了4次比较,因此B选项正确。
分析其他选项:
A(3次)错误:如上所示,需要4次比较才能确定15不在表中
C(5次)错误:过多,二分查找的效率使得不需要这么多次比较
D(6次)错误:更多,对于长度为13的有序表来说,二分查找不可能需要6次比较这里关键是要注意:
\1. 向上取整的处理方式
\2. 每次比较后边界的更新
\3. 由于15不在表中,最后一次比较后确定查找失败
20. 需要实现一个左侧宽度固定,右侧元素自适应,应该在代码中补充那个选项
1 | <div class="container"> |

Flex布局
正确答案: D
在这道题目中,考察了CSS Flex布局中实现左侧固定宽度、右侧自适应布局的知识点。D选项flex: 1是正确答案,因为它能让右侧元素自动填充剩余空间。
flex: 1是flex-grow、flex-shrink和flex-basis的简写属性。当设置flex: 1时,元素会自动扩展占据父容器中的剩余空间,这正是实现右侧自适应的关键。
分析其他选项:
A错误:flex-direction: row只是设置flex容器的主轴方向为水平方向,这是默认值,无法实现自适应布局。B错误:flex-wrap: nowrap控制的是flex项目是否换行,与实现自适应宽度无关。
C错误:align-items: flex-end只是设置交叉轴的对齐方式,将项目对齐到交叉轴的终点,不能实现宽度自适应。
使用flex: 1的优势在于:
\1. 代码简洁,一行代码就能实现自适应
\2. 自适应效果稳定,不受内容多少影响
\3. 兼容性好,主流浏览器都支持
21. 已知一组关键字为 {21, 32, 43, 57, 61, 74, 85},采用链地址法处理冲突,散列表是一个下标从0开始的长度为12的一维数组,散列函数为 H(key) = key MOD 12,则装填因子 α 是()。

数据结构,哈希表
正确答案: A
官方解析:装填因子α是指散列表中实际存储的记录数与散列表长度的比值。
计算过程:
\1. 散列表长度为12(数组下标0-11)
\2. 给定关键字集合{21, 32, 43, 57, 61, 74, 85},计算每个关键字的散列地址:
- H(21) = 21 mod 12 = 9
- H(32) = 32 mod 12 = 8
- H(43) = 43 mod 12 = 7
- H(57) = 57 mod 12 = 9
- H(61) = 61 mod 12 = 1
- H(74) = 74 mod 12 = 2
- H(85) = 85 mod 12 = 1
\3. 关键字总数为7个,散列表长度为12
\4. 因此装填因子α = 7/12A选项7/12是正确答案。
分析其他选项错误原因:
B选项8/12错误:实际记录数是7个而不是8个
C选项7/13错误:散列表长度是12而不是13
D选项8/13错误:既用错了记录数(8),又用错了散列表长度(13)需要注意的是,即使有冲突发生(如21和57映射到9,61和85映射到1),装填因子的计算仍然只考虑实际的关键字个数与散列表长度的比值,与冲突的处理方法无关。
22. 小欧的奇数

1 | const rl = require('readline').createInterface({ |
23. 小欧的GCD
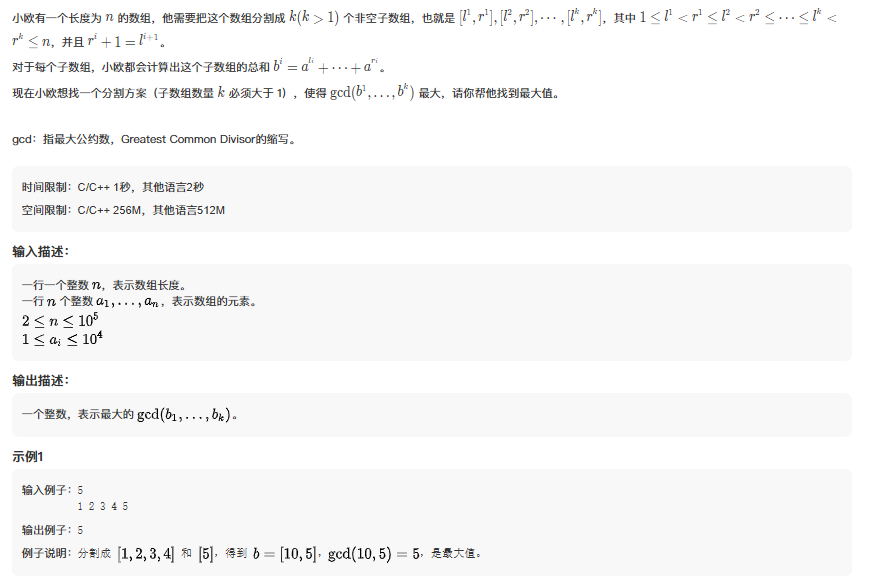
此题的关键在于,分割成两个子数组,就可以解决该问题.分割成更多子数组的gcd不会大于分割成两个子数组的gcd.所以此题只需要找到一个分割点,使得gcd能够被两个子数组的和分别整除即可.
1 | const rl = require('readline').createInterface({ |
 微信
微信 支付宝
支付宝
