字节跳动面试准备2025-06-18
基础技术问题
HTML5
1. 什么是DOCTYPE,有什么作用
在HTML中,文档类型声明是所有文档必须的。<!DOCTYPE html>是HTML5的文档类型声明,它的目的是防止浏览器在渲染文档时使用怪异模式,也就是说,<!DOCTYPE html>文档类型声明确保浏览器会尽力遵循相关规范,而不是使用与某些规范不兼容的不同渲染模式。
文档类型声明不区分大小写,既可以写为<!doctype html>,也可以写成<!DOCTYPE html>。但通常使用大写。
标准模式和怪异模式
在互联网的早期,网页通常以两种版本编写:一种用于
Netscape浏览器,另一种用于IE浏览器。当W3C制定网络标准时,浏览器并不能立即开始使用它们,因为这样会破坏网络上大多数现有的网站。因此,浏览器引入了两种模式,以区别对待符合新标准的新网站和遗留旧网站。现在,网络浏览器的布局引擎使用三种模式:怪异模式、有限怪异模式和无怪异模式。在怪异模式下,布局会模拟 Netscape 4 和 Internet Explorer 5 的行为。这对于支持在广泛采用网络标准之前构建的网站至关重要。在无怪异模式下,行为(希望如此)是现代 HTML 和 CSS 规范中描述的期望行为。在有限怪异模式下,实现的怪异模式数量非常少。
有限怪异模式和无怪异模式过去被称为“准标准”模式和“完全标准”模式。由于这些行为现在已标准化,这些名称已被更改。
对于 HTML 文档,浏览器通过文档开头的 doctype 来决定是使用怪异模式还是无怪异模式。为了确保你的页面使用无怪异模式,请确保你的页面包含类似以下示例的 doctype:
2
3
4
5
6
7
8
9
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Hello World!</title>
></head>
><body></body>
></html>示例中显示的 doctype, <!doctype html> ,是最简单的形式,也是当前 HTML 标准推荐的。早期版本的 HTML 标准推荐其他变体,但如今所有现有的浏览器都会对此 doctype 使用无怪异模式。没有使用更复杂的 doctype 的合理理由。如果你确实使用了其他 doctype,可能会选择一个触发有限怪异模式或怪异模式的 doctype。
将 doctype 放在你的 HTML 文档的最开始,在任何其他内容之前。
<!doctype html> 的唯一目的是激活无怪癖模式。旧版本的 HTML 标准文档类型提供了额外的含义,但没有任何浏览器将文档类型用于切换渲染模式之外的其他用途。
JavaScript 中 document.compatMode 的值将显示文档是否处于怪异模式。如果其值为 “BackCompat” ,则文档处于怪异模式。如果不是,它将具有值 “CSS1Compat” 。
2. HTML结构有哪几部分,分别作用是什么?
<!DOCTYPE> 声明:文档类型声明,告诉浏览器采用标准渲染模式还是怪异渲染模式。<html>:根元素,包含整个网页。主要包含两个部分:<head>和<body>。<head>:这个部分不会直接显示在页面中,而是包含网页的元数据,如标题、描述、关键词、作者、图标、样式表、脚本等。常见的元素包括<title>、<meta>、<link>、<style>、<script>。<body>: 这是页面的主要内容部分,其中包含了要在浏览器窗口中显示的实际内容。如文本,图像,链接等。
3. src和href的区别?
src:
- 嵌入外部资源到当前文档中,资源加载后会替换标签自身位置,成为文档的一部分。
- 处理机制:同步加载资源,阻塞解析,浏览器暂停解析,直到资源加载完成。
- 典型标签
<img><script><iframe><audio><video>
href:
- 用于建立关联关系,指向外部资源(CSS,超链接),资源不会嵌入文档,而是独立存在。
- 处理机制:异步加载资源,不阻塞解析,但是会阻塞渲染。因为没有CSS,无法构建渲染树。
- 典型标签
<a><link>
4. a标签的target属性的取值有哪些,各自有什么作用?
<a>的target属性用于指定链接的打开方式,决定链接内容在何处显示。
_self: 默认值,当前窗口打开链接。_blank: 新窗口打开链接。_parent: 父窗口打开链接。如果没有父窗口,则等同于_self。_top: 顶级窗口打开链接。- 自定义值:自定义的窗口名称,必须与iframe的name属性值一致。
5. meta的作用是什么,有哪些常用属性?
标签是 HTML 文档中位于
区的关键元素,用于提供网页的元数据(metadata)。这些信息不会直接显示给用户,但对浏览器、搜索引擎爬虫、社交媒体平台等机器解析至关重要,直接影响网页的渲染、索引、分享效果和用户体验。核心作用:
- 定义文档的基础属性
- 设置字符编码编码格式:
<meta charset="utf-8">,确保浏览器正确解析多语言字符,避免乱码 - 控制移动端视口宽度:
<meta name="viewport" content="width=device-width, initial-scale=1.0">,实现响应式布局。
- 设置字符编码编码格式:
- 优化搜索引擎(SEO)
- 提供页面描述(description)和关键词(keywords),用于搜索引擎优化。
- 通过robots指令控制爬虫的索引和链接跟踪行为。
- 控制浏览器行为
- 设置缓存策略,自动刷新或跳转,兼容模式
- 增强社交媒体分享
- 配合Open Graph协议或Twitter Card协议,为网页添加元数据,用于社交分享。
- 标准文档信息
- 声明作者,版权信息,网站图标,网站语言等。
6. 什么是空元素?
空元素(Void Elements),也称为空元素或自闭合标签,是 HTML 中不需要闭合标签且不能包含任何子内容(如文本或其他元素)的特殊标签。它们通过属性定义功能,常用于插入独立对象或控制页面结构。以下是详细解析:
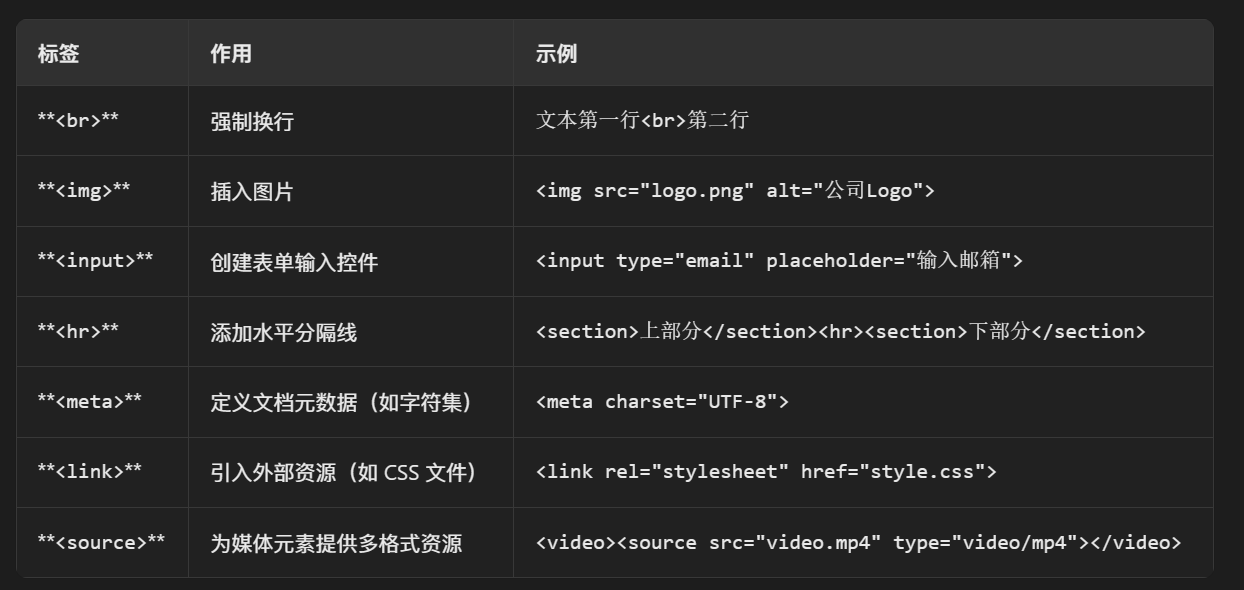
7. 什么是置换元素和非置换元素,有何区别?
置换元素(Peplaced Elements)
- 定义:内容由外部资源或浏览器内部机制决定,不受CSS视觉格式化模型直接控制。浏览器根据元素的标签属性(如
src,type),渲染内容,元素本身具有固有尺寸(宽,高,宽高比) - 特性:内容独立于HTML和CSS(例如图片由src加载,输入框类型由type定义)
- 可以通过CSS设置尺寸(width/height),但实际内容由外部资源驱动
- 部分属性(如
vertical-align)依赖其固有基线(baseline)计算。 - 常见示例:
<img>,<input>,<select>,<video>,<audio>,<iframe>,<canvas>
- 定义:内容由外部资源或浏览器内部机制决定,不受CSS视觉格式化模型直接控制。浏览器根据元素的标签属性(如
非置换元素
- 定义:内容直接由HTML和CSS控制(如字体,颜色,内边距)。
- 可以通过CSS来控制元素的样式和布局
- 常见示例:
<p>,<div>,<span>,
CSS3
JavaScript/ES6+
TypeScript
浏览器
1. 介绍一下浏览器缓存相关的知识
2. 介绍一下浏览器的存储方案
网络
1. HTTP和HTTPS有什么区别?HTTP有什么问题?HTTPS如何避免?
工程化
1. 介绍一下CommonJS和ESModule的区别
2. 介绍一下pnpm的原理
3. 介绍一下Webpack原理和常用配置项
React
小程序&RN
项目经历
1. 项目背景与职责
详细介绍你在腾讯文档负责的“PPT品类格式支持工作”具体是做什么的?这个工作的目标和意义是什么?“提升对Office格式兼容程度”具体指哪些方面兼容?AlloyRenderer是什么?它在整个腾讯文档架构中的作用?
- 清晰定位: “我的核心工作是扩展腾讯文档PPT渲染引擎(AlloyRenderer)的能力,使其能正确解析和渲染更多来自Microsoft Office PowerPoint的复杂格式属性,最终目标是提升用户在腾讯文档中打开和编辑PPT文件时的兼容性和体验,减少格式错乱或功能缺失的情况。”
- 具体化兼容内容: “例如,我主要负责新增了对字体下划线样式(单线、双线、波浪线等)、下划线颜色、特定字体效果(如阴影、轮廓)等格式属性的支持。这些属性在原生Office PPT中很常见,但在之前版本的腾讯文档PPT中可能无法正确显示或编辑。”
- 解释AlloyRenderer: “AlloyRenderer是腾讯文档团队自研的、基于Canvas的渲染引擎。它负责将文档的结构和数据(如文字、形状、图片、格式信息)高效、准确地绘制到画布上。它是整个前端展示层最核心的底层技术之一,直接决定了文档的渲染效果和性能。我的工作就是在它的API层面进行扩展,添加对新格式属性的解析和绘制能力。”
2. 技术难点与解决
问题: 在扩展AlloyRenderer接口支持新格式(如下划线样式和颜色)时,遇到了哪些技术挑战?你是如何解决的?Canvas渲染和DOM渲染在处理这类格式上有何不同?需要考虑哪些性能问题?
- 突出难点: “主要难点在于如何在Canvas环境下精确模拟Office PPT中复杂下划线的效果。Canvas的strokeText或路径绘制API本身没有直接提供类似CSS text-decoration那样丰富的下划线样式。同时,下划线需要与文本基线完美对齐,并且要能处理多行文本、不同字号、缩放等情况。”
- 阐述解决方案:
- 方案设计: “我设计了新的渲染指令接口,让上层业务可以传入下划线类型、颜色、偏移量、线宽等参数。在底层渲染实现上,根据不同的类型(如单线、双线、波浪线),精确计算下划线的路径坐标。对于波浪线这类复杂样式,采用了分段贝塞尔曲线绘制。”
- 精准定位: “为了确保位置准确,需要精确获取文本的基线位置、字体的度量信息(metrics),并在不同缩放比例和DPI下进行适配。可能用到了ctx.measureText()等API。”
- 性能考量: “Canvas渲染是直接操作像素,在大量文本带复杂下划线时,需要优化绘制路径的计算逻辑,避免不必要的重绘。可能采用脏矩形(Dirty Rect)等优化策略(如果了解)。同时,新接口的设计要尽量高效,减少对整体渲染性能的影响。”
- 对比Canvas/DOM: “DOM渲染(如用HTML标签+CSS)实现下划线相对简单直接(用text-decoration或伪元素),浏览器会处理对齐和渲染细节。但Canvas需要开发者手动计算和绘制一切,控制更底层,性能潜力更大(尤其在复杂文档场景),但实现复杂格式的成本更高。”
3. 基建与优化
详细说说你参与的“项目node版本升级和包管理器优化(npm -> pnpm)”。为什么选择pnpm?升级过程中遇到了哪些问题?如何解决的?“安装速度提升120%”这个数据是怎么得出的?升级后除了速度,还有什么其他好处?
- 动机清晰: “项目依赖庞大且复杂,npm的扁平化node_modules结构导致依赖树非常深,存在大量重复依赖(幽灵依赖)和安装空间占用大的问题。安装和构建速度慢,开发体验差。pnpm 通过内容寻址存储和硬链接,能显著减少磁盘空间占用、避免幽灵依赖、并极大提升安装速度。”
- 过程描述: “首先进行了技术调研,确认pnpm对现有项目(包括Webpack、Babel等配置)的兼容性。然后制定了升级方案:更新package.json中的engines字段,在CI/CD流程和本地开发环境安装pnpm,执行pnpm install替换npm install。清理旧的node_modules和package-lock.json是必须的。”
- 问题解决: “主要遇到一些依赖包对pnpm的软链接结构不兼容(尤其是一些老旧的、使用node_modules路径硬编码的包)。解决方案是排查报错,通过pnpm.overrides强制指定兼容版本,或者寻找替代包。需要仔细测试以确保功能正常。”
- 数据量化: “对比升级前后,在相同网络环境和机器配置下,多次执行安装命令计时。npm install平均耗时约X分钟,pnpm install平均耗时约Y分钟,提升比例=(X-Y)/X * 100% ≈ 120%。(务必准备好具体数据!)”
额外收益: “显著减少了node_modules占用的磁盘空间(硬链接共享相同包),消除了幽灵依赖带来的不确定性(依赖必须显式声明),提升了构建确定性(pnpm-lock.yaml更严格),整体开发流程更流畅高效。”
4. Bug修复与用户价值
你提到“主动修复8个历史遗留Bug”,能举1-2个印象深刻的例子吗?你是怎么定位到这些Bug的?修复后如何验证?“用户反馈功能点满意度平均提升3.69%”这个数据是如何收集和计算的?
- 具体案例: “例1: 一个关于文本框内特定字体组合导致换行计算错误,文字重叠的Bug。通过分析渲染日志和Canvas绘制代码,定位到是计算文本宽度时忽略了某些Unicode字符或连字的特殊处理。修复方法是优化宽度计算算法,引入更精准的测量方式。例2: 一个在特定缩放比例下,形状边框颜色渲染不正确的Bug。发现是颜色转换逻辑在特定精度下发生了舍入错误,修改了颜色计算和转换的精度处理。” (选最体现你技术深度和解决问题能力的例子)
- 定位方法: “通过用户反馈渠道(如客服系统、论坛)、内部测试用例、代码审查、以及主动在复杂文档上进行探索性测试发现的。定位方法包括:代码审查相关模块、添加调试日志、使用Chrome DevTools进行Canvas绘制过程调试、断点调试、最小化复现等。”
- 验证方法: “编写或补充对应的单元测试/集成测试用例覆盖修复点;在修复前后,使用包含触发条件的测试文档进行手动验证;进行回归测试确保没有引入新问题。”
- 数据解释: “这个数据来源于团队的NPS(净推荐值)或用户满意度调研问卷。针对PPT品类相关的功能点(如格式兼容性、稳定性),在修复Bug的版本发布后一段时间(如1-2周),对比修复前的用户评分。计算相关功能点的平均得分提升值。(了解数据来源和计算方法,能自圆其说即可)”
5. 技术文档和影响力
你沉淀了12篇技术文档,主要关于哪些内容?为什么觉得这些文档重要?后续实习同学反馈如何?体现了你的什么能力?
- 内容范围: “文档主要包括:1)AlloyRenderer新接口的使用指南和示例;2)项目中遇到的复杂Bug的分析与解决方案复盘;3)pnpm迁移的详细操作手册和最佳实践;4)项目环境配置、开发调试技巧;5)特定模块(如文本渲染、格式处理)的内部实现原理和注意事项。”
- 强调价值: “这些文档极大地降低了新同学熟悉庞大且复杂项目的门槛,避免了重复踩坑,快速上手具体开发任务(如格式支持)。同时也作为团队的知识沉淀,方便成员间共享经验和技术细节。”
- 反馈与影响: “后续实习同学反馈这些文档非常实用,帮助他们快速理解了项目关键部分和开发流程,节省了大量摸索时间。Leader也认可这些文档对团队效率的提升。”
- 体现能力: “这体现了我的总结归纳能力、技术写作能力、分享精神和团队协作意识。能够将实践经验和知识系统化地传递下去,对团队效能是长期有益的。”
个人特质和字节匹配度
1. 学习能力
你是如何快速上手腾讯文档这样复杂的大型项目的?最近在学习什么新技术?怎么学习的?
1)阅读文档:项目文档、AlloyRenderer API文档、团队Wiki。
2)请教同事:积极向导师和资深同事请教架构和业务逻辑。
3)调试与日志:通过Chrome DevTools、添加调试日志理解代码执行流程和数据流。
4)从小处着手:从修复简单Bug开始,逐步深入核心模块。” 提到最近学习的内容(如深入React原理、Vite、某个新框架、构建优化),说明学习途径(官方文档、源码、技术博客、动手实践)。
2. 解决问题的能力
举一个你解决过的最有挑战性的技术问题的例子(不一定在腾讯)。
提取主题色
- k-means
- 八叉树
中卫切分
rust
- webassembly
- web workers
 微信
微信 支付宝
支付宝
