红宝书学习
概述
- 介绍JavaScript的起源:从哪里来,如何发展,以及现今的状况。这一章会谈到JavaScript与ECMAScript的关系,DOM,BOM,以及ECMA和W3C相关的标准。
- 介绍JavaScript如何与HTML结合起来创建动态网页,主要介绍在网页中嵌入JavaScript的不同方式,还有JavaScript的内容类型及其与
<script>元素的关系。 - 介绍语言的基本概念,包括语法和流控制语句;解释JavaScript与其他类C语言在语法上的异同点。在讨论内置操作符时也会谈到强制类型转换。此外还将介绍所有的原始类型,包括Symbol。
- 探索JavaScript松散类型下的变量处理。这一章将涉及原始类型和引用类型的不同,以及与变量有关的执行上下文。此外,这一章也会讨论JavaScript中的垃圾回收,涉及在变量超出作用域时如何回收内存。
- 讨论JavaScript所有内置的引用类型。如Date, Regexp,原始类型及其包装类型。每种引用类型既有理论上的讲解,也有相关浏览器实现的剖析。
- 继续讨论内置引用类型,包括Object,Array,Map,WeakMap,Set和WeakSet等。
- 介绍ECMAScript新版中引入的两个基本概念:迭代器和生成器,并分别讨论他们最基本的行为和在当前语言环境下的应用。
- 解释如何在JavaScript中使用类和面向对象编程。首先会深入讨论JavaScript的Object类型,进而探讨原型式继承,接下来全面介绍ES6类及其与原型式继承的紧密关系。
- 介绍两个紧密相关的概念:Proxy(代理)和反射(Reflect)API。代理和反射用于拦截和修改这门语言的基本操作。
- 探索JavaScript最强大的一个特性:函数表达式,主要涉及闭包,this对象,模块模式,创建私有对象成员,箭头函数,默认参数和扩展操作符。
- 介绍两个紧密相关的异步编程构造:Promise类型和async/await。这一章讨论JavaScript的异步编程范式,进而介绍promise与异步函数的关系。
- 介绍BOM,即浏览器对象模型,跟与浏览器本身交互的API相关。所有BOM对象都会涉及,包括window,document,location,navigator和screen等。
- 解释检测客户端机器及其能力的不同手段,包括能力检测和用户代理字符串检测。这一章讨论每种手段的优缺点,以及适用场景。
- 介绍DOM,即文档对象模型,主要是DOM Level 1定义的API。这一章将简单讨论XML及其与DOM的关系,进而全面探索DOM以及如何利用它操作网页。
- 解释其他DOM API,包括浏览器本身对DOM的扩展,主要涉及Selectors API和Element Traversal API 和HTML5扩展。
- 在之前两章的基础上,解释DOM Level 2和Level 3对DOM的扩展,包括新增的属性,方法和对象。这一章还会介绍DOM4的相关内容,比如Mutaion Observer。
- 解释事件在JavaScript中的本质,以及事件的起源及其在DOM中的运行方式。
- 围绕
<canvas>标签讨论如何创建动态图形,包括2D和3D上下文(WebGL)等动画和游戏开发所需的基础。这一章还会讨论WebGL1和WebGL2. - 探索使用JavaScript增强表单交互及突破浏览器限制,主要讨论文本框,选择框等表单元素及数据验证和操作。
- 介绍各种JavaScript API,包括Atomics,Encoding,File,Blob,Notifications,Streams,Timing,Web Components和Web Cryptography。
- 讨论浏览器如何处理JavaScript代码中的错误及集中错误处理方式。这一章同时介绍了每种浏览器的调试工具和技术,包括简化调试过程的建议。
- 介绍通过JavaScript读取和操作XML数据的特性,解释了不同浏览器支持特性和对象的差异,提供了简化跨浏览器编码的建议。这一章也讨论了使用XSLT在客户端转换XML数据。
- 介绍作为XML替代的JSON数据格式,还讨论了浏览器原生解析和序列化JSON,以及适用JSON时要注意的安全问题。
- 讨论浏览器请求数据和资源的常用方式,包括早期的XMLHttpRequest对象,以及现代的Fetch API。
- 讨论应用程序离线时在客户端机器上存储数据的各种技术。先从cookie谈起,然后讨论Web Storage 和 IndexedDB。
- 介绍模块模式在编码中的应用,进而讨论ES6模块之前的模块加载方式,包括CommonJS,AMD和UMD。最后介绍新的ES6模块及其正确用法。
- 深入介绍专用工作者线程,共享工作者线程和服务工作者线程。其中包括工作者线程在操作系统和浏览器层面的实现,以及使用各种工作者线程的最佳策略。
- 讨论在企业级开发中进行JavaScript编码的最佳实践。其中提到了提升代码可维护性的编码惯例,包括编码技巧,格式化及通用编码建议。深入讨论应用性能和提升速度的技术。最后介绍上线与部署相关的话题,包括项目构建流程。
第1章 什么是JavaScript
本章内容
- JavaScript历史回顾
- JavaScript是什么
- JavaScript与ECMAScript的关系
- JavaScript的不同版本
这里这张图个人认为有点问题,DOM应该属于BOM,DOM是BOM的一部分,不应该和BOM并列。
ECMA-262到底定义了什么?
- 语法
- 类型
- 语句
- 关键字
- 保留字
- 操作符
- 全局对象
DOM

DOM级别
1998年10月,DOM Level 1成为W3C的推荐标准。该规范由两个模块组成:DOM Core和DOM HTML。前者提供了一种映射XML文档,从而方便访问和操作文档任意部分的方式;后者扩展了前者,并增加了特定于HTML的对象和方法。
注意DOM并非只能通过JavaScript操作,也可以通过其他语言操作。不过对于浏览器来说,DOM就是使用ECMAScript实现的,如今已经成为JavaScript语言的一大组成部分。
DOM Level 1的目标是映射文档结构,而DOM Level2的目标则宽泛的多。增加了对鼠标和用户界面事件,范围,遍历(迭代DOM节点的方法)的支持,而且通过对戏那个接口支持了CSS。另外,DOM Level1 中的DOM Core也被扩展以包含对XML命名空间的支持。
DOM Level 2新增了以下模块:
- DOM视图:描述追踪文档不同视图(如应用CSS样式前后的文档)
- DOM事件:描述事件及事件处理的接口
- DOM样式:描述处理元素CSS样式的接口
- DOM遍历和范围:描述遍历和操作DOM树的接口
DOM Level 3增加了以统一方式加载和保存文档的方法(包含在DOM Load and Save新模块中),还有验证文档的方法(DOM Validation)。在Level 3中,DOM Core模块被扩展,支持了所有XML1.0的特性,包括XML Infoset,XPath 和XML Base。
目前,W3C不再按照Level来维护DOM了,而是作为DOM Living Standard来维护,其快照成为DOM4. DOM4新增的内容包括替代Mutaion Events的Mutation Observers。
其他DOM
除了DOM Core和DOM HTML接口,其他语言也发布了自己的DOM标准,下面列出的语言是基于XML的,每一种都增加了该语言独有的DOM方法和接口。
- 可伸缩矢量图(SVG, Scalable Vector Graphics)
- 数学标记语言(MathML, Mathematical Markup Language)
- 同步多媒体集成语言(SMIL, Synchronized Multimedia Integration Language)
此外还有一些语言也开发了自己的DOM实现,比如Mozilla的XML用户界面语言(XUL, XML User Interface Language),不过,只有前面列表中的语言是W3C推荐的标准。
BOM
HTML5涵盖了尽可能多的BOM特性。
总体来说,BOM主要针对浏览器窗口和子窗口(frame),不过人们通常会把任何特定于浏览器的扩展都归在BOM的范畴内。比如,下面就是这样一些扩展:
- 弹出新浏览器窗口的能力
- 移动,缩放和关闭浏览器窗口的能力
- navigator对象,提供关于浏览器的详尽信息
- location对象,提供浏览器加载页面的详尽信息
- screen对象,提供关于用户屏幕分辨率的详尽信息
- performance对象,提供浏览器内存占用,导航行为和事时间统计的详尽信息
- 对cookie的支持
- 其他自定义对象,如XMLHttpRequest
小结
JavaScript是一门用来与网页交互的脚本语言,包含以下三个组成部分。
- ECMAScript:由ECMA-262定义并提供的核心功能
- DOM:提供与网页内容交互的方法和接口
- BOM:提供与浏览器交互的方法和接口
第2章 HTML中的JavaScript
本章内容
- 使用
<script>元素- 行内脚本与外部脚本比较
- 文档模式对JavaScript有什么影响
- 确保JavaScript不可用时的用户体验
将JavaScript插入HTML的主要方法是使用<script>元素,这个元素已经被正式加入HTML规范。
<script>元素有下列8个属性:
- src:可选。表示包含要执行的代码的外部文件。
- async:可选。表示应该立即开始下载脚本,但是不能阻止页面其他动作,比如下载资源或等待其他脚本加载。只对外部脚本有效。
- charset:可选。使用src属性指定的代码字符集。这个属性很少使用,因为大多数浏览器不在乎它的值。
- crossorigin:可选。配置相关请求的CORS(跨域资源共享)设置。默认不使用CORS。
crossorigin="anonymous"配置文件请求不必设置凭据标志。crossorigin="use-credentials"设置凭据标志,意味着出站请求会包含凭据。 - defer:可选。表示脚本可以延迟到文档完全被解析和显示之后再执行。只对外部脚本有效。
- integrity:可选。允许比对接收到的资源和指定的加密签名以验证子资源完整性(SRI, Subresource Integrity)。如果接收到的资源的签名与这个属性指定的签名不匹配,则页面会报错,脚本不会执行。这个属性可用于确保CDN不会提供恶意内容。
- language: 废弃。最初用于表示代码块中的脚本语言(如”JavaScript”、”JavaScript 1.2”
或”VBScript”)。大多数浏览器都会忽略这个属性,不应该再使用它。 - type:可选。代替language,表示代码块中脚本语言的类型(也称为MIME类型)。按照惯例,这个值始终都是”text/javascript”.尽管”text/javascript”和”text/ecmascript”都已经废弃了。JavaScript的MIME类型是”application/x-javascript”,不过给type属性这个值可能导致脚本被忽略。在非IE的浏览器中有效的其他值还有”application/javascript”和”application/ecmascript”。如果这个值是module,则代码会被当做ES6模块,而且只有这时候,代码中才能出现import和export。
使用<script>的方式有两种:
- 行内脚本:将脚本放在
<script>元素的内容中。 - 外部脚本:将脚本放在外部文件中,并使用src属性将外部脚本引入HTML文档中。
浏览器解析行内脚本的方式决定了它在看到字符串</script>时,会将其当成结束的</script>标签。想避免这个问题,只需要传递转义字符\即可:
1 | <script> |
注意:使用了src属性的
<script>元素不应该在<script>和</script>之间包含其他JavaScript代码。如果两者都提供的话,浏览器只会下载并执行脚本文件,从而忽略行内代码。
<script>标签的src属性可以引入外部域的脚本文件,不受浏览器同源策略的限制。
但是这个可能会导致安全问题,使用<script>标签的integrity属性是防范这种问题的一个武器,但这个属性也不是所有浏览器都支持。
在没有使用async和defer的情况下,浏览器会按照<script>标签在页面中出现的顺序依次解释他们。
使用了defer的脚本会在浏览器解析到结束的</html>标签后才会执行。HTML5规范要求脚本应该按照他们出现的顺序执行,因此第一个推迟的脚本会在第二个推迟的脚本之前执行,而且两者都在DOMContentLoaded事件之前执行。
使用了async的脚本会在页面的load事件之前执行,但可能会在DOMContentLoaded事件之前或之后执行,而且无法保证脚本的顺序。所以,在async脚本中,不要对DOM进行操作。
动态加载脚本
除了<script>标签,还有其他方式可以加载脚本。因为JavaScript可以使用DOM API,所以通过DOM中动态添加script元素同样可以加载指定的脚本。只要创建一个script元素并将其添加到DOM即可。
1 | let script = document.createElement('script'); |
默认情况下,以这种方式创建的<script>元素是异步加载的,相当于添加了async属性。
以这种方式获取的资源对浏览器预加载器是不可见的。这会严重影响他们在资源获取队列中的优先级。这种方式可能会严重影响性能。要想让浏览器预加载器直到这些动态请求文件的存在,可以在文档头部显式声明他们:
1 | <link rel="preload" href="gibberish.js"> |
文档模式
IE5.5发明了文档模式的概念,即可以使用DOCTYPE来切换文档模式。最初的文档模式有两种:
- 怪异模式/混杂模式(quirks mode)
- 标准模式(standards mode)
在HTML文件中第一行的代码,目的就是告诉浏览器使用标准模式解析文档,不要使用怪异模式。
1 |
<noscript>元素
针对早期浏览器不支持 JavaScript 的问题,需要一个页面优雅降级的处理方案。最终,<noscript>
元素出现,被用于给不支持 JavaScript 的浏览器提供替代内容。虽然如今的浏览器已经 100%支持
JavaScript,但对于禁用 JavaScript 的浏览器来说,这个元素仍然有它的用处。<noscript>元素可以包含任何可以出现在<body>中的 HTML 元素,<script>除外。在下列两种
情况下,浏览器将显示包含在<noscript>中的内容:
- 浏览器不支持脚本
- 浏览器对脚本的支持被关闭
任何一个条件被满足,包含在<noscript>中的内容就会被渲染。否则,浏览器不会渲染<noscript>中的内容。
1 |
|
第3章 语言基础
3.1 语法
- 变量名区分大小写
- 标识符:变量,函数,属性或函数参数的名称:
- 第一个字符必须是字母,下划线,或美元符
- 后续字符可以是字母,数字,下划线,或美元符
标识符中的字母可以是扩展ASCII(Extended ASCII)中的字母,也可以是Unicode的字母字符。
3.2 严格模式
ECMAScript 5 引入了严格模式(strict mode)。严格模式是一种不同的JavaScript解析和执行模型,ECMAScript3的一些不规范写法在这种模式下会被处理,对于不安全的活动将抛出错误。
可以在整个文件或某个函数中开启严格模式,只需要加上"use strict";
1 |
1 | function doSomething() { |
3.3 分号插入
在JavaScript中,分号;是可选的,但是为了避免错误,还是建议加上分号。
3.4 关键字与保留字


这些词汇不能用作标识符,但现在还可以用作对象的属性名。一般来说,最好还是不要使用关键字
和保留字作为标识符和属性名,以确保兼容过去和未来的 ECMAScript 版本。
3.5 变量
ECMAScript 变量是松散类型的,意思是变量可以用于保存任何类型的数据。每个变量只不过是一个用于保存任意值的命名占位符。有 3 个关键字可以声明变量:var、const 和 let。其中,var 在ECMAScript 的所有版本中都可以使用,而 const 和 let 只能在ECMAScript 6 及更晚的版本中使用。
| 关键字 | var |
let |
const |
|---|---|---|---|
| 作用域 | 函数作用域 | 块级作用域 | 块级作用域 |
| 初始化 | 可以不初始化,值为undefined | 可以不初始化,值为undefined | 必须初始化 |
| 提升 | 提升到函数作用域顶部 | TDZ暂时性死区 | TDZ暂时性死区 |
| 重复声明 | 后者覆盖前者 | ReferenceError | ReferenceError |
| 重复赋值 | 更新为新值 | 更新为新值 | 重新赋值会导致运行时错误,但是可以改变对象的属性值 |
| 全局声明 | 称为window对象的属性 | 不会挂载到全局对象 | 不会挂载到全局对象 |
for循环中的let声明
在let出现之前,for循环定义的迭代变量会渗透到循环体外部:
1 | for (var i = 0; i < 5; i++) { |
改用let之后,这个问题就消失了,因为迭代变量的作用域仅限于for循环块的内部:
1 | for (let i = 0; i < 5; i++) { |
在使用var的时候,最常见的问题就是对迭代变量的奇特声明和修改:
1 | for (var i = 0; i < 5; i++) { |
你可能以为会输出0,1,2,3,4
实际上会输出5,5,5,5,5
之所以会这样,是因为在退出循环时,迭代变量保存的是导致循环退出的值:5.在之后执行超时逻辑时,所有的i使用的都是同一个变量,因为输出的都是同一个最终值。
而在使用let声明迭代变量时,JavaScript在后台会为每个迭代循环声明一个新的迭代变量。每个setTimeout引用的都是不同的变量实例,所以console.log输出的是我们期望的值,也就是循环执行过程中每个迭代变量的值。
1 | for (let i = 0; i < 5; i++) { |
这种每次迭代声明一个独立变量实例的行为适用于所有风格的for循环。包括for-in和for-of循环。
JavaScript引擎会为for循环中的let声明分别创建独立的变量实例,虽然const变量跟let变量很相似,但是不能用const来声明迭代变量(因为迭代变量会自增)
1 | for (const i = 0; i < 10; i++) // TypeError: Assignment to constant variable |
不过,可以用const声明一个不会被修改的for循环变量。也就是说,每次迭代只是创建一个新变量。这对for-of和for-in循环特别有意义。
1 | let i = 0; |
3.6 声明风格最佳实践
- 不使用var
- const优先,let次之
3.7 数据类型
ECMAScript中有7中简单数据类型(也称为原始类型):
- Undefined
- Null
- Boolean
- Number
- BigInt
- String
- Symbol
还有一种复杂数据类型叫Object.
Object是一种无序键值对的集合。
typeof 操作符
因为 ECMAScript 的类型系统是松散的,所以需要一种手段来确定任意变量的数据类型。typeof 操作符就是为此而生的。对一个值使用 typeof 操作符会返回下列字符串之一:
- “undefined”表示未定义;
- “boolean”表示值为布尔值
- “string”表示值为字符串
- “number”表示值为数值
- “bigint”表示大整形
- “object”表示值为对象(而不是函数)或null
- “function”表示值为函数
- “symbol”表示值为符号
下面是使用typeof操作符的例子
1 | let message = "some string"; |
在这个例子中,我们把一个变量(message)和一个数值字面量传给了 typeof 操作符。注意,因为 typeof 是一个操作符而不是函数,所以不需要参数(但可以使用参数)。 注意typeof在某些情况下返回的结果可能会让人费解,但技术上讲还是正确的。比如,调用typeof null 返回的是”object”。这是因为特殊值 null 被认为是一个对空对象的引用
注意 严格来讲,函数在 ECMAScript 中被认为是对象,并不代表一种数据类型。可是, 函数也有自己特殊的属性。为此,就有必要通过 typeof 操作符来区分函数和其他对象。
Undefined类型
Undefined 类型只有一个值,就是特殊值 undefined。当使用 var 或 let 声明了变量但没有初始化时,就相当于给变量赋予了 undefined 值:
1 | let message; |
在这个例子中,变量 message 在声明的时候并未初始化。而在比较它和 undefined 的字面值时, 两者是相等的。这个例子等同于如下示例:
1 | let message = undefined; |
这里,变量 message 显式地以 undefined 来初始化。但这是不必要的,因为默认情况下,任何未 经初始化的变量都会取得 undefined 值。
注意 一般来说,永远不用显式地给某个变量设置 undefined 值。字面值 undefined 主要用于比较,而且在 ECMA-262 第 3 版之前是不存在的。增加这个特殊值的目的就是为了正式明确空对象指针(null)和未初始化变量的区别。
注意,包含 undefined 值的变量跟未定义变量是有区别的。请看下面的例子:
1 | let message; // 这个变量被声明了,只是值是undefined |
在上面的例子中,第一个 console.log 会指出变量 message 的值,即”undefined”。而第二个 console.log 要输出一个未声明的变量 age 的值,因此会导致报错。对未声明的变量,只能执行一个 有用的操作,就是对它调用 typeof。(对未声明的变量调用 delete 也不会报错,但这个操作没什么用, 实际上在严格模式下会抛出错误。)
在对未初始化的变量调用 typeof 时,返回的结果是”undefined”,但对未声明的变量调用它时, 返回的结果还是”undefined”,这就有点让人看不懂了。比如下面的例子:
1 | let message; // 这个变量被声明了,只是值是undefined |
无论是声明还是未声明,typeof 返回的都是字符串”undefined”。逻辑上讲这是对的,因为虽然 严格来讲这两个变量存在根本性差异,但它们都无法执行实际操作。
即使未初始化的变量会被自动赋予 undefined 值,但我们仍然建议在声明变量的 同时进行初始化。这样,当 typeof 返回”undefined”时,你就会知道那是因为给定的变 量尚未声明,而不是声明了但未初始化。
undefined 是一个假值。因此,如果需要,可以用更简洁的方式检测它。不过要记住,也有很多 其他可能的值同样是假值。所以一定要明确自己想检测的就是 undefined 这个字面值,而不仅仅是 假值。
1 | let message; // 这个变量被声明了,只是值为 undefined |
Null类型
Null类型同样只有一个值,就是特殊值null.逻辑上讲,null值表示一个空对象指针,这也是给typeof 传一个null会返回”object”的原因。
1 | let car = null; |
在定义将来要保存对象值的变量时,建议使用 null 来初始化,不要使用其他值。这样,只要检查 这个变量的值是不是 null 就可以知道这个变量是否在后来被重新赋予了一个对象的引用,比如:
1 | if (car != null) { |
undefined 值是由 null 值派生而来的,因此 ECMA-262 将它们定义为表面上相等,如下面的例 子所示:
1 | console.log(null == undefined); // true |
用等于操作符(==)比较 null 和 undefined 始终返回 true。但要注意,这个操作符会为了比较 而转换它的操作数(本章后面将详细介绍)。
即使 null 和 undefined 有关系,它们的用途也是完全不一样的。如前所述,永远不必显式地将 变量值设置为 undefined。但 null 不是这样的。任何时候,只要变量要保存对象,而当时又没有那个 对象可保存,就要用 null 来填充该变量。这样就可以保持 null 是空对象指针的语义,并进一步将其 与 undefined 区分开来。
null 是一个假值。因此,如果需要,可以用更简洁的方式检测它。不过要记住,也有很多其他可 能的值同样是假值。所以一定要明确自己想检测的就是 null 这个字面值,而不仅仅是假值。
1 | let message = null; |
Boolean类型
Boolean(布尔值)类型是 ECMAScript 中使用最频繁的类型之一,有两个字面值:true 和 false。 这两个布尔值不同于数值,因此 true 不等于 1,false 不等于 0。下面是给变量赋布尔值的例子:
1 | let found = true; |
注意,布尔值字面量 true 和 false 是区分大小写的,因此 True 和 False(及其他大小混写形式) 是有效的标识符,但不是布尔值。
虽然布尔值只有两个,但所有其他 ECMAScript 类型的值都有相应布尔值的等价形式。要将一个其他类型的值转换为布尔值,可以调用特定的 Boolean()转型函数:
1 | let message = "Hello World"; |
在这个例子中,字符串message会被转换为布尔值并保存在变量messageAsBoolean中。
Boolean()转型函数可以在任意类型的数据上调用,而且始终返回一个布尔值。什么值能转换为 true 或 false 的规则取决于数据类型和实际的值。下表总结了不同类型与布尔值之间的转换规则。
| 数据类型 | 转换为true的值 | 转换为false的值 |
|---|---|---|
| Boolean | true | false |
| String | 非空字符串 | “”(空字符串) |
| Number | 非零数值(包括无穷值) | 0, NaN |
| BigInt | 非零的任意值 | 0 |
| Object | 任意对象 | null |
| Undefined | —- | undefined |
Number类型
Number类型使用IEEE754格式表示整数和浮点数。
最基本的是十进制,直接写出来即可。
1 | let intNum = 55; |
整数也可以使用8进制,或16进制。
- 8进制:以0o开头,然后是相应的的八进制数字(0-7),如果字面量中包含的数字超出了应有的范围,就会忽略前缀的零,后面的数字序列会被当成十进制,如下所示:
1 | let octalNum1 = 0o70; // 八进制的56 |
八进制字面量在严格模式下是无效的,会导致JavaScript引擎抛出语法错误。
- 16进制:以0x(区分大小写)开头,然后是16进制的数字(0-9,A-F).16进制中数字中的字母大小写均可。下面是例子:
1 | let hexNum = 0xA; // 十六进制10 |
使用八进制和十六进制格式创建的数值在所有数学操作中都被视为十进制数值。
浮点值
要定义浮点值,数值中必须包含小数点,且小数点后面必须至少有一个数字。虽然小数点前面不是必须有整数,但推荐加上。
1 | let floatNum1 = 1.1; |
因为存储浮点数使用的内存空间是存储整数值的两倍,所以ECMAScript总是想方设法把值转换为整数。
在小数点后面没有数字的情况下,数值就会变成整数。类似地,如果数值本身就是整数,只是小数点后面跟着0(如1.0),那它也会被转换为整数。
1 | let floatNum1 = 1.; // 小数点后面没有数字,当成整数1处理 |
对于非常大或者非常小的数值,浮点值可以用科学计数法来表示。
1 | let floatNum = 3.1235e7; // 等于31250000 |
0.1 + 0.2 !== 0.3
永远不要测试某个浮点数的值!!!
值的范围
由于内存限制,ECMAScript并不支持表示这个世界上的所有数值。ECMAScript可以表示的最小数值保存在Number.MIN_VALUE中,这个值在大多数浏览器中是5e-324;可以表示的最大数值保存在Nubmer.MAX_VALUE中,这个值在多数浏览器中是1.7976931348623157e+308.
如果某个计算得到的结果超出了JavaScript可以表示的范围,那么这个数值会被自动转换为一个特殊的Infinity(无穷值).任何无法表示的负数以-Infinity来表示,任何无法表示的正数以Infinity来表示。
如果计算返回正 Infinity 或负 Infinity,则该值将不能再进一步用于任何计算。这是因为 Infinity 没有可用于计算的数值表示形式。要确定一个值是不是有限大(即介于 JavaScript 能表示的 最小值和最大值之间),可以使用 isFinite()函数,如下所示:
1 | let result = Number.MIN_VALUE + Number.MAX_VALUE; |
在计算非常大和非常小的数的时候,有必要检测一下是否超出范围。
NaN
有一个特殊的数值叫NaN,意思是“不是数值”(Not a Number),用来表示本来要返回数值的操作失败了(而不是抛出错误).比如,用0除任意数值在其他语言中通常会导致错误,从而终止代码执行。但在ECMAScript中,0,+0,-0相除会返回NaN.
1 | console.log(0 / 0); |
NaN有几个独特的属性:
- 任何涉及NaN的操作始终返回NaN(例如NaN/10).
- NaN不等于包括NaN在内的任何值。
1 | console.log(NaN == NaN); // false |
为此,ECMAScript设置了isNaN()函数。该函数接收一个参数,可以是任意数据类型,然后判断这个参数是否“不是数值”。把一个值传给isNaN()后,该函数会尝试把它转换为数值。某些非数值的值可以直接转换为数值,例如字符串”10”或布尔值。任何不能转换为数值的值都会导致这个函数返回true。举例如下:
1 | console.log(isNaN(NaN)); // true |
NaN也可以用来测试对象。对象会首先调用
[Symbol.toPrimitive]()方法,如果未定义,则接着调用valueOf()方法,然后再确定返回的值能否转换为数值。如果不能,再调用toString()方法,并测试其返回值。
1 | let obj = { |
数值转换
有3个函数可以将非数值转换为数值:Number(),parseInt(),parseFloat()。Number是转型函数,可以用于任何数据类型。后两个函数主要用于将字符串转换为数值。对于同样的参数,这3个函数执行的操作也不同。
Number()函数基于如下规则进行转换:
布尔值,true转换为1,false转换为0
数值,直接返回
null,返回0
undefined,返回NaN
字符串,应用如下规则:
如果字符串包含数值字符,包括数值字符前面带加减号的情况,则转换为一个十进制数值。
因此,Number(“1”)返回1,Number(“123”)返回123,Number(“011”)返回11(忽略前面的0)
如果字符串包含有效的浮点值格式如“1.1”,则会转换为相应的浮点值(同样,忽略前面的零)
如果字符串包含有效的十六进制格式如“0xf”,则会转换为与该十六进制对应的十进制整数值
如果是空字符串(不包含字符)则返回0
如果字符串包含上述情况之外的字符,则返回NaN
对象,依次调用
[Symbol.toPrimitive](),valueOf(),toString()方法,并按照上述规则转换返回的值。
一元加操作符与Number()函数遵循相同的转换规则
考虑到用Number函数转换字符串时相对复杂且有点反常规,通常在需要得到整数时,可以优先使用parseInt()函数。parseInt()函数更专注于字符串是否包含数值模式。字符串最前面的空格会被忽略,从第一个非空格字符开始转换。如果第一个字符不是数值字符,加号或减号,parseInt()立即返回NaN。这意味着空白字符串也会返回NaN(这一点跟Number()不一样,Number返回0)。如果第一个字符是数值字符,加号或减号,则继续依次检测每个字符,直到字符串末尾,或碰到非数值字符。比如”1234blue”会被转换为1234.因为blue会被完全忽略。类似的”22.5”会被转换为22,因为小数点不是有效的整数字符。
假设字符串中的第一个字符是数值字符,parseInt()函数也能识别不同的整数格式(十进制,十六进制).换句话说,如果字符串以”0x”开头,就会被解释为16进制整数。
1 | let num1 = parseInt("1234blue"); // 1234 |
不同的数值格式很容易混淆,因此parseInt()也接受第二个参数,用于指定底数(进制数)。如果直到要解析的是16进制,那么可以传入16作为第二个参数,以便正确解析。
1 | let num = parseInt("0xAF", 16); // 175 |
在这个例子中,第一个转换是正确的,而第二个转换失败了。区别在于第一次传入了进制数作为参 数,告诉 parseInt()要解析的是一个十六进制字符串。而第二个转换检测到第一个字符就是非数值字 符,随即自动停止并返回 NaN。
parseFloat()函数的工作方式跟parseInt()函数类型,都是从位置0开始检测每个字符。同样,它也是解析到字符串末尾或者解析到一个无效的浮点数值字符为止。这意味着第一次出现的小数点是有效的,但是第二次出现的小数点就无效了,此时字符串中剩余字符都会被忽略。因此,”22.34.5”将会被转换为22.34。
parseFloat()函数的另一个不同之处在于,它始终忽略字符串开头的0.这个函数能识别前面讨论的所有浮点格式,以及十进制格式(开头的0将会被忽略)。十六进制数值始终会返回0.因为parseFloat()直解析十进制值,因此不能指定底数。最后,如果字符串表示整数(没有小数点或者小数点后面只有一个零),则parseFloat()返回整数。
1 | let num1 = parseFloat("1234blue"); // 1234,按整数解析 |
String类型
String数据类型表示0或多个16位Unicode字符序列。字符串可以使用双引号,单引号或反引号标识。
1 | let firstName = "John"; |
引号的开头和结尾要匹配,使用同一种引号
1 | let firstName = 'lksdjfkljds"; // 语法错误 |
字符串字面量
| 字面量 | 含义 |
|---|---|
\n |
换行 |
\t |
制表 |
\b |
退格 |
\r |
回车 |
\f |
换页 |
\\ |
反斜杠 |
\' |
单引号,在字符串以单引号标示时使用,例如'He said, \'hey.\'' |
\" |
双引号,在字符串以双引号标示时使用,例如"He said, \"hey.\"" |
| \` | 反引号,在字符串以双引号标示时使用. |
\xnn |
以十六进制编码nn表示的字符(其中n是十六进制数字0-F),例如\x41等于”A” |
\unnnn |
以十六进制nnnn表示的Unicode字符 |
这些字符字面量可以出现在字符串中的任意位置,且可以作为单个字符被解释:
1 | let text = "This is the letter sigma: \u03a3."; |
在这个例子中,即使包含 6 个字符长的转义序列,变量 text 仍然是 28 个字符长。因为转义序列表示一个字符,所以只算一个字符。字符串的长度可以通过其 length 属性获取: console.log(text.length); // 28 这个属性返回字符串中 16 位字符的个数。
| 返回值 | 属性/方法 | 适用场景 |
|---|---|---|
| UTF-16 码元数量 | string.length |
基础字符串操作(需注意代理对) |
| 实际字符数(码点数) | [...str].length |
精确字符统计(含辅助平面字符) |
| 物理字节数(需指定编码) | Buffer.byteLength() |
网络传输、存储空间计算 |
字符串特点
ECMAScript中的字符串是不可变的(immutable),意思是一旦创建,他们的值就不能变了。要修改某个变量中的字符串值,必须先销毁原始的字符串,然后将包含新值的另一个字符串保存到该变量,如下所示:
1 | let lang = "Java"; |
这里,变量 lang 一开始包含字符串”Java”。紧接着,lang 被重新定义为包含”Java”和”Script” 的组合,也就是”JavaScript”。
整个过程会首先分配一个足够容纳10个字符的空间,然后填充上”Java”和”Script”。最后销毁原始的字符串”Java”和字符串”Script”,因为这两个字符串都没有用了。所有处理都是在后台发生的,而这也是一些早期的浏览器(如 Firefox 1.0 之前的版本和 IE6.0)在 拼接字符串时非常慢的原因。这些浏览器在后来的版本中都有针对性地解决了这个问题。
转换为字符串
有两种方式把一个值转换为字符串。首先是几乎所有值都有的toString()方法。这个方法唯一的作用就是返回当前值的字符串等价物。
1 | let age = 11; |
toString()方法可见于数值,布尔值,对象和字符串值(没错,字符串也有toString()方法,该方法只是简单地返回自身的一个副本)。
null和undefined没有toString()方法。
多数情况下,toString()方法不接收任何参数。不过,在数值调用这个方法时,可以接收一个底数参数,即以什么底数来输出数值的字符串表示。默认情况下,toString()返回数值的十进制字符串表示。可以通过传入参数修改。
1 | let num = 10; |
如果你确定一个值不是null或undefined,可以使用String()转型函数,他始终会返回表示相应类型值的字符串。String()函数遵循如下规则。
- 如果值有
toString()方法,则调用该方法(不传参数)并返回结果。 - 如果值是
null, 返回"null" - 如果值是
undefined,返回"undefined"
1 | let value1 = 10; |
模板字面量
模板字面量与单引号和双引号不同,模板字面量会保留换行字符,可以跨行定义字符串。
1 | let myMultiLineString = 'first line\nsecond line'; |
由于模板字面量会保持反引号内部的空格,因此在使用时要格外注意。格式正确的模板字符串看起
来可能会缩进不当:
1 | // 这个模板字面量在换行符之后有 25个空格符 |
字符串插值
1 | let value = 5; |
所有插入的值都会使用String()强制转型为字符串
模板字面量标签函数
模板字面量也支持定义标签函数(tag function),而通过标签函数可以自定义插值行为。标签函数会接收被插值记号分隔后的模板和对每个表达式求值的结果。
标签函数本身就是一个常规函数,通过前缀到模板字面量来应用自定义行为,如下例所示。标签函数接收到的参数依次是原始字符串数组和对每个表达式求值的结果。这个函数的返回值是对模板字面量求值得到的字符串。
1 |
|
如果想返回默认的字符串,可以这样做:
1 | let a = 6; |
原始字符串
使用模板字面量也可以直接获取原始的模板字面量内容(如换行符或Unicode字符),而不是被转换后的字符表示。为此,可以使用默认的String.row标签函数。
1 | // Unicode 示例 |
也可以通过标签函数的第一个参数,即字符串数组的.raw属性取得每个字符串的原始内容。
1 |
|
Symbol类型
符号是原始值,且符号实例是唯一,不可变的。符号的用途是确保对象属性使用唯一标识符,不会发生属性冲突的危险。
符号就是用来创建唯一记号,进而用作非字符串形式的对象属性。
1. 符号的基本用法
符号需要使用Symbol()函数初始化。因为符号本身就是原始类型,所以typeof操作符对符号返回symbol.
1 | let sym = Symbol(); |
调用Symbol函数时,也可以传入一个字符串参数作为对于符号的描述,将来可以通过这个字符串来调试代码。但是,这个字符串参数与符号定义或标识完全无关。
1 | let genericSymbol = Symbol(); |
符号没有字面量语法,这也是他们发挥作用的关键。按照规范,你只要创建Symbol实例并将其用作对象的新属性,就可以保证它不会覆盖已有的对象属性,无论是符号属性还是字符串属性。
1 | let genericSymbol = Symbol(); |
更重要的是,Symbol()函数不能直接与new关键字一起作为构造函数使用。这样做是为了避免创建符号包装对象,戏那个使用Boolean, String, Number那样,他们都支持构造函数且可用于初始化包含原始值的包装对象。
1 | let myBoolean = new Boolean(); |
如果你确实想使用包装对象,可以借用Object函数
1 | let mySymbol = Symbol(); |
2. 使用全局符号注册表
如果运行时的不同部分需要共享和重用符号实例,那么可以用一个字符串作为键,在全局符号注册表中创建并重用符号。
为此,需要使用Symbol.for()方法:
1 | let fooGlobalSymbol = Symbol.for('foo'); |
Symbol.for对每个字符串键都执行幂等操作。第一次使用某个字符串调用时,它会检查全局运行时注册表,发现不存在对应的符号,于是就会生成一个新符号实例并添加到注册表中。后续使用相同字符串的调用同样会检查注册表,发现存在与该字符串对应的符号,然后就会返回该符号实例。
即使采用相同的符号描述,在全局注册表中定义的符号跟使用Symbol定义的符号也并不等同;
1 | let localSymbol = Symbol('foo'); |
全局注册表中的符号必须使用字符串键来创建,因此作为参数传给Symbol.for()的任何值都会被转换为字符串。此外,注册表中使用的键同时也会被用作符号描述。
1 | let emptyGlobalSymbol = Symbol.for(); |
还可以使用Symbol.keyFor()来查询全局注册表,这个方法接收符号,返回该全局符号对应的字符串键。如果查询的不是全局符号,则返回undefined。
1 | // 创建全局符号 |
如果传递给Symbol.keyFor()的不是符号,则该方法抛出TypeError
1 | // 传递参数非符号 |
3. 使用符号作为属性
凡是可以使用字符串或数值作为属性的地方,都可以使用符号。这就包括了对象字面量属性和Object.defineProperty()/Object.defineProperties()定义的属性。对象字面量只能在计算属性语法中使用符号作为属性。
1 | let s1 = Symbol('foo'), |
类似于Object.getOwnPropertyNames()返回对象实例的常规属性数组,Object.getOwnPropertySymbols()返回对象实例的符号属性数组。这两个方法的返回值彼此互斥。Object.getOwnPropertyDescription()会返回同时包含常规和符号属性描述符的对象。Reflect.ownKeys()会返回两种类型的键:
1 | let s1 = Symbol('foo'), |
因为符号属性是对内存中符号的一个引用,所以直接创建并用作属性的符号不会丢失。但是,如果没有显式地保存对这些属性的引用,那么必须遍历对戏那个的所有符号属性才能找到相应的属性键:
1 | let o = { |
4. 内置的符号
内置符号都以Symbol工厂函数字符串属性的形式存在。
这些内置符号的最重要的用途之一就是重新定义他们,从而改变原生结构的行为。比如,我们知道for-of循环会在相关对象上使用Symbol.iterator属性,那么就可以通过在自定义对象上重新定义Symbol.iterator的值,来改变for-of在迭代该对象时的行为。
这些内置符号也没有什么特别之处,他们就是全局函数Symbol的普通字符串属性,指向一个符号的实例。所有内置符号属性都是不可写,不可枚举,不可配置的。
注意:在ECMAScript规范中,常常会引用符号在规范中的名称,前缀为@@. 比如,@@iterator指的就是Symbol.iterator.
1. Symbol.asyncIterator
作为一个属性表示**一个方法,该方法返回对象默认的AsyncIterator。由for-await-of语句使用。换句话说,这个符号表示实现异步迭代器API的函数。
for-await-of循环会利用这个函数执行异步迭代操作。循环时,他们会调用以Symbol.asyncIterator为键的函数,并期望这个函数会返回一个实现迭代器API的对象。很多时候,返回的对象是实现该API的AsyncGenerator:
1 | class Foo { |
技术上,这个由Symbol.asyncIterator函数生成的对象应该通过其next()方法陆续返回Promise实例。可以通过显式地调用next()方法返回,也可以隐式地通过异步生成器函数返回。
1 | class Emitter { |
2. Symbol.hasInstance
作为一个属性表示一个方法,该方法决定一个构造器对象是否认可一个对象是它的实例,由instanceof 操作符使用。instanceof 操作符可以用来确定一个对象实例的原型链上是否有原型。instanceof的典型使用场景如下:
1 | function Foo() {}; |
在ES6中,instanceof 操作符会使用Symbol.hasInstance函数来确定关系。以Symbol.hasInstance为键的函数会执行同样的操作,只是操作数对掉了一下。
1 | function Foo() {}; |
这个属性定义在Function的原型上,因此默认在所有函数和类上都可以调用。由于instanceof操作符会在原型链上寻找这个属性定义,就跟在原型链上寻找其他属性一样,因此可以在继承的类上通过静态方法重新定义这个函数。
1 | class Bar {} |
3. Symbol.isConcatSpreadable
作为一个属性表示**一个布尔值,如果是true,则意味着对象应该用Array.prototype.concat()打平其数组元素。
ES6中的Array.prototype.concat方法会根据接收到的对象类型选择如何将一个类数组对戏那个拼接成数组实例。覆盖Symbol.isConcatSpreadable的值可以修改这个行为.
数组对象默认情况下会被打平到已有的数组,false或假值会导致整个对象被追加到数组末尾。类数组对象默认情况下会被追加到数组末尾,true或真值会导致整个对象被打平到数组实例。其他不是类数组对象的对象中在Symbol.isConcatSpreadable被设置为true的情况下将会被忽略。
1 | let initial = ['foo']; |
4. Symbol.iterator
作为一个属性表示一个方法,该方法返回对象默认的迭代器。
由for-of语句使用。换句话说,这个符号实现迭代器API的函数。
for-of循环这样的语言结构会利用这个函数执行迭代操作。循环时,他们会调用Symbol.iterator为键的函数,并默认这个函数会返回一个实现迭代器API的对象。很多时候,返回的对象是实现该API的Generator
1 | class Foo { |
技术上,这个由Symbol.iterator函数生成的对象应该通过其next()方法陆续返回值。可以通过显式地调用next()方法返回,也可以隐式地通过生成器函数返回。
1 | class Emitter { |
5. Symbol.match
作为一个属性表示一个正则表达式方法,该方法用正则表达式去匹配字符串。由String.prototype.match()方法使用。String.prototype.match()方法会使用以Symbol.match为键的函数来对这个正则表达式求值。正则表达式的原型上默认有这个函数的定义,因此所有正则表达式实例默认是这个String方法的有效参数。
1 | class FooMatcher { |
6. Symbol.replace
作为一个属性表示一个正则表达式方法,该方法替换一个字符串中匹配的子串。由String.prototype.replace()方法使用。String.prototypr.replace()方法会使用以Symbol.replace为键的函数来对正则表达式求值。正则表达式的原型上默认有这个函数的定义,因此所有正则表达式实例默认是这个String方法的有效参数。
1 | console.log(RegExp.prototype[Symbol.replace]); |
给这个方法传入非正则表达式值会导致该值被自动转换为RegExp对象。如果想改变这种行为,让方法直接使用参数,可以重新定义Symbol.replace函数以取代默认对正则表达式求值的行为,从而让replace()方法使用非正则表达式实例。Symbol.replace函数接收两个参数,即调用replace()方法的的字符串实例和替换字符串。返回的值没有限制。
1 | class FooReplacer { |
7. Symbol.search
作为一个属性表示一个正则表达式方法,该方法中返回字符串中匹配正则表达式的索引。由String.prototype.search()方法使用。String.prototype.search()方法会使用以Symbol.search()为键的函数来对整个正则表达式求值。正则表达式原型上默认有这个函数,因此所有正则表达式实例默认是这个String方法的有效参数。
1 | console.log(RegExp.prototype[Symbol.search]); |
给这个方法传入非正则表达式值会导致该值被转换为 RegExp对象。如果想改变这种行为,让方法直接使用参数,可以重新定义 Symbol.search 函数以取代默认对正则表达式求值的行为,从而让search()方法使用非正则表达式实例。Symbol.search 函数接收一个参数,就是调用 search()方法的字符串实例。返回的值没有限制:
1 | class FooSearcher { |
8. Symbol.species
作为一个属性表示*一个函数值,该函数作为创建派生功能对象的构造函数。这个属性在内置类型中最常用,用于对内置类型实例方法返回值暴露实例化派生对象的方法。用Symbol.species定义静态的获取器(getter)方法,可以覆盖新创建实例的原型定义。
简单来说,例如map,slice等返回新的对象的方法,默认返回原来的类型,但是如果修改了Symbol.species,则会返回其中定义的新类型。
1 | class Bar extends Array { }; |
9. Symbol.split
作为一个属性表示一个正则表达式方法,该方法在匹配正则表达式的索引位置拆分字符串。有String.prototype.split()方法使用。String.prototype.
split()方法会使用以 Symbol.split 为键的函数来对正则表达式求值。正则表达式的原型上默认有这个函数的定义,因此所有正则表达式实例默认是这个 String 方法的有效参数:
1 | console.log(RegExp.prototype[Symbol.split]); |
给这个方法传入非正则表达式值会导致该值被转换为 RegExp对象。如果想改变这种行为,让方法直接使用参数,可以重新定义 Symbol.split函数以取代默认对正则表达式求值的行为,从而让 split()方法使用非正则表达式实例。Symbol.split 函数接收一个参数,就是调用 split ()方法的字符串实例。返回的值没有限制:
1 | class FooSplitter { |
10. Symbol.toPrimitive
作为一个属性表示一个方法,该方法将对象转换为相应的原始值。由ToPrimitive抽象操作使用。很多内置操作都会常识强制将对象转换为原始值,包括字符串,数值和未指定的原始类型。对于一个自定义对象实例,通过在这个实例的Symbol.toPromitive属性上定义一个函数可以改变默认行为。
根据提供给这个函数的参数(string, number, default),可以控制返回的原始值:
1 | class Foo { } |
11. Symbol.toStringTag
作为一个属性表示一个字符串,该字符串用于创建对象的默认字符串描述。由内置方法Object.prototype.toString()使用。
通过toString()方法获取对象标识时,会检索由Symbol.toStringTag指定的实例标识符,默认为”Object”.内置类型已经指定了这个值,但自定义类实例还需要明确定义。
1 | let s = new Set(); |
12. Symbol.unscopables
作为一个属性表示一个对象,该对象所有的以及继承的属性,都会从关联对象的with环境绑定中排除。设置这个符号并让其映射对应属性的键值为true,就可以阻止该属性出现在with环境绑定中,如下例所示:
1 | let o = { foo: 'bar' }; |
注意:不推荐使用with,也不推荐使用Symbol.unscopables
Object类型
ECMAScript中的对象其实就是一组数据和功能的集合。对象通过new操作符后跟对象类型的名称来创建。开发者可以通过创建Object类型的实例来创建自己的对象,然后给对象添加属性和方法:
1 | let o = new Object(); |
这个语法类似 Java,但 ECMAScript 只要求在给构造函数提供参数时使用括号。如果没有参数,如上面的例子所示,那么完全可以省略括号(不推荐):
1 | let o = new Object; // 合法,但不推荐 |
Object的实例本身并不是很有用,但是理解与它相关的概念非常重要。类似于Java中的java.lang.Object,ECMAScript中Object也是派生其他对象的基类。Object类型的所有属性和方法在派生的对象上同样存在。
每个Object实例都有如下属性和方法:
constructor:用于创建当前对象的函数。在前面的例子中,这个值就是Object()函数hasOwnProperty(propertyName): 用于判断当前对象实例(不是原型)上是否存在给定的属性。要检查的属性名必须是字符串(如o.hasOwnProperty("name"))或符号。isPrototypeof(Object):判断当前对象是否为另一个对象的原型。propertyIsEnumerable(propertyName): 用于判断给定的属性是否可以使用for-in语句枚举。与hasOwnProperty()不同,属性名必须是字符串,因为符号一定不能别for-in枚举。toLocalString():返回对象的字符串表示,该字符串反映对象所在的本地化执行环境。toString():返回对象的字符串表示valueOf():返回对象对应的字符串,数值或布尔值表示。通常与toString()的返回值相同。

3.8 操作符
- 一元操作符
- 位操作符
- 布尔操作符
- 乘性操作符
- 指数操作符
- 加性操作符
- 关系操作符
- 相等操作符
- 条件操作符
- 赋值操作符
- 逗号操作符
第4章 变量,作用域与内存
本章内容
- 通过变量使用原始值与引用值
- 理解执行上下文
- 理解垃圾回收
相比于其他语言,JavaScript 中的变量可谓独树一帜。正如 ECMA-262 所规定的,JavaScript 变量是松散类型的,而且变量不过就是特定时间点一个特定值的名称而已。由于没有规则定义变量必须包含什么数据类型,变量的值和数据类型在脚本生命期内可以改变。这样的变量很有意思,很强大,当然也有不少问题。本章会剖析错综复杂的变量。
4.1 原始值与引用值
4.1.1 动态属性
4.1.2 复制值
4.1.3 传递参数
ECMAScript中所有函数的参数都是按值传递的。
1 | function setName(obj) { |
对象类型传递的也是值,只不过值的内容是一个地址。修改函数内部对象本身的值,不会影响到外部,只有通过函数内部对象值的引用访问堆内存,进行修改才会影响到外部值。
ECMAScript中函数的参数就是局部变量。
4.2 执行上下文和作用域
执行上下文(简称“上下文”)在JavaScript中非常重要。变量或函数的上下文决定了他们可以访问哪些数据,以及他们的行为。每个上下文都有一个关联的变量对象。而这个上下文中定义的所有变量和函数都存在于这个对象上。虽然无法通过代码访问变量对象,但后台处理数据会用到它。
全局上下文时最外层的上下文。根据ECMAScript实现的宿主环境,表示全局上下文的对象可能不一样。在浏览器中,全局上下文就是我们常说的window对象,因此所有通过var定义的全局变量和函数都会成为window对象的属性和方法。
使用let和const的顶级声明不会定义在全局上下文中,但在作用域链解析上效果是一样的。上下文在其所有代码都执行完毕后会被销毁。包括定义在它上面的所有变量和函数(全局上下文在应用程序退出前才会被销毁,比如关闭网页或退出浏览器)。
每个函数调用都有自己的上下文。当代码执行流进入函数时,函数的上下文被推到一个上下文栈上。在函数执行完之后,上下文栈会弹出该上下文,将控制权返还给之前的执行上下文。ECMAScript程序的执行流就是通过这个上下文栈进行控制的。
上下文中的代码在执行的时候,会创建一个对象的作用域链。这个作用域链决定了各级上下中的代码在访问变量和函数时的顺序。代码正在执行的上下文的变量对象始终位于作用域链的最前端。如果上下文是函数,则其活动对象用足变量对象。活动对象最初只有一个定义变量:arguments(全局上下文中没有这个变量).作用域链中的下一个变量对象来自包含上下文,再下一个对象来自下一个包含上下文。以此类推直至全局上下文。全局上下文的变量对象始终是作用域链的最后一个变量对象。
代码执行时的标识符解析是通过眼作用域链逐级搜索标识符名称完成的。搜索过程始终从作用域链的最前端开始,然后逐级往后,直到找到标识符。(如果没有标识符,通常会报错)
1 | var color = "blue"; |
对于这个例子而言,函数changeColor()的作用域链包含两个对象:一个是它自己的变量对象(就是定义arguments对象的那个),另一个就全局上下文的变量对象。这个函数内部之所以能够访问变量color,就是因为可以在作用域链中找到它。
此外,局部作用域中定义的变量可用于在局部上下文中替换全局变量。
1 | var color = "blue"; |
以上代码涉及 3 个上下文:全局上下文、changeColor()的局部上下文和 swapColors()的局部上下文。全局上下文中有一个变量 color和一个函数 changeColor()。 changeColor()的局部上下文中有一个变量 anotherColor和一个函数 swapColors(),但在这里可以访问全局上下文中的变量 color。swapColors()的局部上下文中有一个变量 tempColor,只能在这个上下文中访问到。全局上下文和changeColor()的局部上下文都无法访问到 tempColor。而在 swapColors()中则可以访问另外两个上下文中的变量,因为它们都是父上下文。图 4-3 展示了前面这个例子的作用域链。
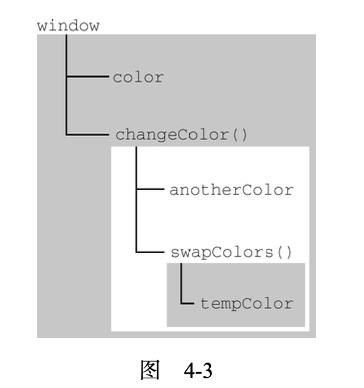
图 4-3 中的矩形表示不同的上下文。内部上下文可以通过作用域链访问外部上下文中的一切,但外部上下文无法访问内部上下文中的任何东西。上下文之间的连接是线性的、有序的。每个上下文都可以到上一级上下文中去搜索变量和函数,但任何上下文都不能到下一级上下文中去搜索。swapColors()局部上下文的作用域链中有 3 个对象: swapColors()的变量对象、 changeColor()的变量对象和全局变量对象。swapColors()的局部上下文首先从自己的变量对象开始搜索变量和函数,搜不到就去搜索上一级变量对象。changeColor()上下文的作用域链中只有 2 个对象:它自己的变量对象和全局变量对象。因此,它不能访问 swapColors()的上下文。
函数参数被认为是当前上下文中的变量,因此也跟上下文中的其他变量遵循相同的访问规则。
4.2.1 作用域链增强
虽然执行上下文主要有全局上下文和函数上下文两种(eval()调用内部存在第三种上下文),但有其他方式来增强作用域链。某些语句会导致在作用域链前端临时添加一个上下文,这个上下文在代码执行后会被删除。通常在两种情况下会出现这个现象,即代码执行到下面任意一种情况时:
- try/catch语句的catch块
- with语句
这两种情况下,都会在作用域链前端添加一个变量对象。对with语句来说,会向作用域链前端添加指定的对象;对catch语句而言,则会创建一个新的变量对象,这个变量对象会包含要抛出的错误对象的声明。
1 | function buildUrl() { |
这里,with 语句将 location 对象作为上下文,因此 location 会被添加到作用域链前端。buildUrl()函数中定义了一个变量 qs。当 with 语句中的代码引用变量 href 时,实际上引用的是location.href,也就是自己变量对象的属性。在引用 qs时,引用的则是定义在 buildUrl()中的那个变量,它定义在函数上下文的变量对象上。而在 with 语句中使用 var 声明的变量url 会成为函数上下文的一部分,可以作为函数的值被返回;但像这里使用 let声明的变量 url,因为被限制在块级作用域(稍后介绍),所以在 with块之外没有定义。
4.2.2 变量声明
在使用 var 声明变量时,变量会被自动添加到最接近的上下文。在函数中,最接近的上下文就是函数的局部上下文。在 with 语句中,最接近的上下文也是函数上下文。如果变量未经声明就被初始化了,那么它就会自动被添加到全局上下文,如下面的例子所示:
1 | function add(num1, num2) { |
这里,函数 add()定义了一个局部变量 sum,保存加法操作的结果。这个值作为函数的值被返回,但变量 sum 在函数外部是访问不到的。如果省略上面例子中的关键字 var,那么 sum 在 add()被调用之后就变成可以访问的了,如下所示:
1 | function add(num1, num2) { |
这一次,变量 sum 被用加法操作的结果初始化时并没有使用 var 声明。在调用 add()之后,sum被添加到了全局上下文,在函数退出之后依然存在,从而在后面可以访问到。
var 声明会被拿到函数或全局作用域的顶部,位于作用域中所有代码之前。这个现象叫作“提升”(hoisting)。提升让同一作用域中的代码不必考虑变量是否已经声明就可以直接使用。可是在实践中,提升也会导致合法却奇怪的现象,即在变量声明之前使用变量。下面的例子展示了在全局作用域中两段等价的代码:
4.3 垃圾回收
JavaScript是使用垃圾回收的语言,也就是说执行环境负责在代码执行时管理内存。在C和C++等语言中,跟踪内存使用对开发者来说是一个很大的负担,也是很多问题的来源。JavaScript为开发者卸下了这个负担,通过自动内存管理实现内存分配和闲置资源的回收。基本思路很简单:确定哪个变量不会再使用,然后释放它占用的内存。这个过程是周期性的,即垃圾回收程序每隔一定时间(或者说在代码执行过程中某个预定的收集时间)就会自动运行。垃圾回收过程是一个近似且不完美的方案,因为某块内存是否还有用,属于不可判定的问题,意味着靠算法是解决不了的。
主要有两种方式:标记清理和引用计数
4.3.1 标记清理
JavaScript最常用的垃圾回收策略是标记清理(mark-and-sweep)。当变量进入上下文,比如在函数内部声明一个变量时,这个变量就会被加上存在于上下文中的标记。而在上下文中的变量,逻辑上讲,永远不应该释放他们的内存,因为只要上下文中的代码在运行,就有可能用到他们。当变量离开上下文时,也会被加上离开该上下文的标记。
给变量加标记的方式有很多种。比如,当变量进入上下文时,反转某一位;或者可以维护“在上下文中”和“不在上下文中”两个变量列表,可以把变量从一个列表转移到另一个列表。标记过程的实现方式并不重要,关键是策略。
垃圾回收程序运行的时候,会标记内存中存储的所有变量(记住,标记方法有很多种)。然后,它会将所有在上下文中的变量,以及被在上下文中的变量引用的变量的标记去掉。在此之后还有标记的变量就是待删除的了,原因是任何上下文中的变量都访问不到他们了。随后垃圾回收程序做一次内存清理,销毁带标记的所有值并回收他们的内存。
4.3.2 引用计数
另一种没那么常用的垃圾回收策略是引用计数(reference counting)。其思路是对每个值都记录它被引用的次数。声明变量并给它赋一个引用值时,这个值的引用数为 1。如果同一个值又被赋给另一个变量,那么引用数加 1。类似地,如果保存对该值引用的变量被其他值给覆盖了,那么引用数减 1。当一个值的引用数为 0 时,就说明没办法再访问到这个值了,因此可以安全地收回其内存了。垃圾回收程序下次运行的时候就会释放引用数为 0 的值的内存。
引用计数最早由 Netscape Navigator 3.0 采用,但很快就遇到了严重的问题:循环引用。所谓循环引用,就是对象 A 有一个指针指向对象 B,而对象 B 也引用了对象 A。比如:
1 | function problem() { |
4.3.3 性能
垃圾回收程序会周期性运行,如果内存中分配了很多变量,则可能造成性能损失,因此垃圾回收的时间调度很重要。尤其是在内存有限的移动设备上,垃圾回收有可能会明显拖慢渲染的速度和帧速率。
开发者不知道什么时候运行时会收集垃圾,因此最好的办法是在写代码时就要做到:无论什么时候开始收集垃圾,都能让它尽快结束工作。
现代垃圾回收程序会基于对 JavaScript 运行时环境的探测来决定何时运行。探测机制因引擎而异,但基本上都是根据已分配对象的大小和数量来判断的。比如,根据 V8 团队 2016 年的一篇博文的说法:
“在一次完整的垃圾回收之后, V8 的堆增长策略会根据活跃对象的数量外加一些余量来确定何时再次垃
圾回收。”
由于调度垃圾回收程序方面的问题会导致性能下降, IE 曾饱受诟病。它的策略是根据分配数,比如分配了 256 个变量、4096 个对象/数组字面量和数组槽位(slot) ,或者 64KB 字符串。只要满足其中某个条件,垃圾回收程序就会运行。这样实现的问题在于,分配那么多变量的脚本,很可能在其整个生命周期内始终需要那么多变量,结果就会导致垃圾回收程序过于频繁地运行。由于对性能的严重影响,IE7最终更新了垃圾回收程序。IE7 发布后, JavaScript 引擎的垃圾回收程序被调优为动态改变分配变量、字面量或数组槽位等会触发垃圾回收的阈值。 IE7 的起始阈值都与 IE6 的相同。如果垃圾回收程序回收的内存不到已分配的 15%,这些变量、字面量或数组槽位的阈值就会翻倍。如果有一次回收的内存达到已分配的 85%,则阈值重置为默认值。这么一个简单的修改,极大地提升了重度依赖 JavaScript 的网页在浏览器中的性能。
4.3.4 内存管理
在使用垃圾回收的编程环境中,开发者通常无需关心内存管理。不过,JavaScript运行在一个内存管理与垃圾回收都很特殊的环境。分配给浏览器的内存通常比分配给桌面软件的要少很多,分配给移动浏览器的就更少了。这更多出于安全考虑而不是别的,就睡位了避免运行大量JavaScript的网页耗尽系统内存而导致操作系统崩溃。这个内存限制不仅影响变量分配,也影响调用栈以及能够同时在一个线程中执行的语句数量。
将内存占用量保持在一个较小的值可以让页面性能更好。优化内存占用的最佳手段就是保证在执代码时只保存必要的数据。如果数据不在需要,就把它设置为null,从而释放其引用。这也可以叫做解除引用。这个建议最适合全局变量和全局对象的属性。局部变量在超出作用域后会被自动解除引用,如下面的例子:
1 | function createPerson(name) { |
在上面的代码中,变量globalPerson保存着createPerson()函数调用返回的值。在createPerson()内部,localPerson创建了一个对象并给它添加了一个name属性。然后,localPerson作为函数值被返回,并赋值给globalPerson。localPerson在 createPerson()执行完成超出上下文后会自动被解除引用,不需要显式处理。但 globalPerson 是一个全局变量,应该在不再需要时手动解除其引用,最后一行就是这么做的。
第5章 基本引用类型
本章内容
- 理解对象
- 基本JavaScript数据类型
- 原始值与原始值包装类型
5.1 Date
静态方法
- Date.parse()
- Date.UTC()
- Date.now()
实例方法
- toDateString()
- toTimeString()
- toLocalDateString()
- toLocalTimeString()
- toUTCString()
第6章 集合引用类型
6.1 Object
6.2 Array
6.3 定型数组
6.3.1 历史
6.3.2 ArrayBuffer
Float32Array实际上是一种“视图”,可以允许JavaScript在运行时访问一块名为ArrayBuffer的预分配内存。ArrayBuffer是所有定型数组及视图引用的基本单位。
ArrayBuffer()是一个普通的JavaScript构造函数,可以用于在内存中分配特定数量的字节空间。
1 | const buf = new ArrayBuffer(16); // 在内存中分配16字节 |
ArrayBuffer一经创建就不能再调整大小。不过,可以使用slice()复制其全部或部分到一个新的实例中:
1 | const buf1 = new ArrayBuffer(16); |
不能仅仅通过对ArrayBuffer的引用就读取或写入其内容。要读取或写入ArrayBuffer,就必须通过视图。视图有不同的类型,但引用的都是ArrayBuffer中存储的二进制数据。
6.3.3 DataView
第一种允许你读写ArrayBuffer的视图是DataView。这个视图专门为文件I/O和网络I/O设计,其API支持对缓冲数据的高度控制,但相比于其他类型的视图性能也差一些。DataView对缓冲内容没有任何预设,也不能迭代。
必须对已有的ArrayBuffer读取或写入时才能创建DataView实例。这个实例可以使用全部或部分ArrayBuffer,且维护着对缓冲实例的引用,以及视图在缓冲中开始的位置。
1 | const buf = new ArrayBuffer(16); |
要通过DateView读取缓冲,还需要几个组件。
- 首先是要读或写的字节偏移量。可以用看成DataView中的某种地址。
- DateView应该使用ElementType来实现JavaScript的Number类型到缓冲内二进制格式的转换
- 最后是内存中值的字节序。默认为大端字节序。
- ElementType
DataView对存储在缓冲内的数据类型没有预设。它暴露的API强制开发者在读,写时指定一个ElementType,然后DataView就会忠实地为读,写而完成相应的转换。
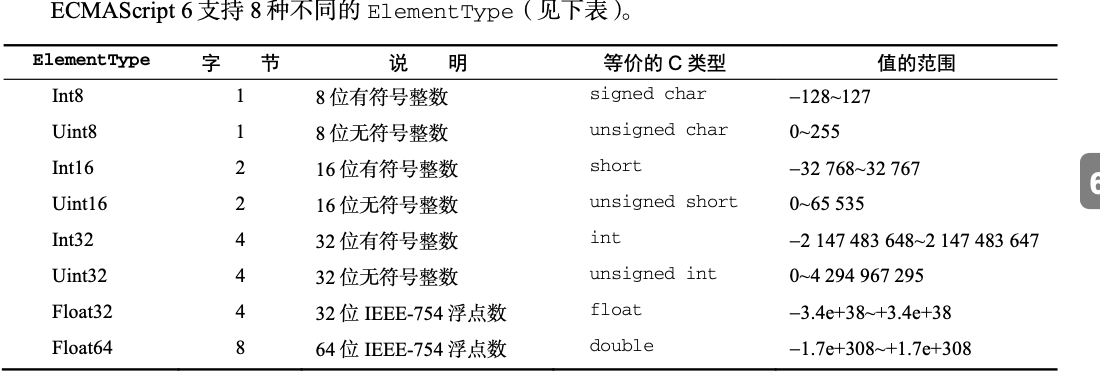
DataView为上表中的每种类型都暴露了get和set方法,这些方法使用byteOffset(字节偏移量)定位要读取或写入值的位置。类型是可以互换使用的。
1 | // 在内存中分配两个字节并声明一个DataView |
- 字节序
前面例子中的缓冲回避了字节序的问题。字节序是计算系统维护的一种字节顺序的约定。DataView只支持两种约定:大端字节序和小端字节序。大端字节序也称为“网络字节序”,意思是最高有效位保存在第一个字节,而最低有效位保存在最后一个字节。小端字节序正好相反,即最低有效位保存在第一个字节,最高有效位保存在最后一个字节。
JavaScript 运行时所在系统的原生字节序决定了如何读取或写入字节,但 DataView 并不遵守这个约定。对一段内存而言,DataView 是一个中立接口,它会遵循你指定的字节序。DataView 的所
有 API 方法都以大端字节序作为默认值,但接收一个可选的布尔值参数,设置为 true 即可启用小端字节序。
1 | // 在内存中分配两个字节并声明一个 DataView |
6.4 Map
6.5 WeakMap
6.6 Set
6.7 WeakSet
第7章 迭代器和生成器
第8章 对象,类与面向对象编程
本章内容
理解对象
理解对象创建过程
理解继承
理解类
8.1 理解对象
8.2 创建对象
8.2.1 概述
8.2.2 工厂模式
8.2.3 构造函数模式
8.2.4 原型模式
8.2.5 对象迭代
8.3 继承
8.4 类
8.4.1 类定义
8.4.2 类构造函数
1. 实例化
使用new调用类的构造函数会执行以下操作
- 在内存中创建一个新的对象
- 这个新对象的内部[[Prototype]]指针被赋值为构造函数的prototype属性
- 构造函数内部的this被赋值为这个新对象
- 执行构造函数内部的代码(给新对象添加属性)
- 如果构造函数返回非空对象,则返回该对象,范泽,返回刚创建的新对象
8.4.3 实例,原型和类成员
8.4.4 继承
- 抽象基类
new.target保存通过new关键字调用的类或函数。
第9章 代理与反射
本章内容
- 代理基础
- 代码捕获器与反射方法
- 代理模式
1 | const target = { |
9.1 代理基础
9.1.1 创建空代理
9.1.2 定义捕获器
使用代理的主要目的是可以定义捕获器(trap)。捕获器就是在处理程序对象中定义的“基本操作的拦截器”。每个处理程序对象可以包含0个或多个捕获器,每个捕获器都应该对应一种基本操作,可以直接或间接在代理对象上调用。每次在代理对象上调用这些基本操作时,代理可以在这些操作传播到目标对象之前先调用捕获器函数,从而拦截并修改相应的行为。
1 | const target = { |
9.1.3 捕获器参数和反射API
所有捕获器都可以访问相应的参数,基于这些参数可以重建被捕获方法的原始行为。比如,get()捕获器会接收到目标对象,要查询的属性和代理对象三个参数。
1 | const target = { |
有了这些参数,就可以重建别捕获的方法的原始行为
1 | const target = { |
9.1.4 捕获器不变式
9.1.5 可撤销的代理
有时候可能需要中断代理对象与目标对象之间的联系。对于使用 new Proxy()创建的普通代理来说,这种联系会在代理对象的生命周期内一直持续存在。
Proxy 也暴露了 revocable()方法,这个方法支持撤销代理对象与目标对象的关联。撤销代理的操作是不可逆的。而且,撤销函数(revoke())是幂等的,调用多少次的结果都一样。撤销代理之后再调用代理会抛出 TypeError。撤销函数和代理对象是在实例化时同时生成的:
1 | const target = { |
9.1.6 实用反射API
某些情况下应该优先使用反射API。
- 反射API与对象API
在使用反射API时,要记住:
- 反射API并不限于捕获处理程序
- 大多数反射API在Object类型上都有对应的方法
通常,Object上的方法适用于通用程序,而反射方法适用于细粒度的对象控制与操作。
- 状态标记
很多反射方法返回称作状态标记的布尔值,表示意图执行的操作是否成功。有时候,状态标记比哪些返回修改后的对象或抛出错误的反射API更有用。例如,可以使用反射API对下面的方法进行重构。
1 | // 初始代码 |
在定义新属性时如果发生问题,Reflect.defineProperty()会返回 false,而不是抛出错误。因此使用这个反射方法可以这样重构上面的代码:
1 | // 重构后的代码 |
以下反射方法都会提供状态标记:
- Reflect.defineProperty()
- Reflect.preventExtensions()
- Reflect.setPrototypeOf()
- Reflect.set()
- Reflect.deleteProperty()
以下反射方法可以代替操作符
- Reflect.get():代替对象属性访问操作符
- Reflect.set():代替=赋值操作符
- Reflect.has():代替in操作符或with()
- Reflect.deleteProperty():可以代替delete操作符
- Reflect.construct(): 可以代替new操作符
9.1.7 代理另一个代理
9.1.8 代理的问题与不足
9.2 代理捕获器与反射方法
9.3 代理模式
第10章 函数
10.1 箭头函数
10.2 函数名
所有函数对象都会暴露一个只读的name属性,其中包含关于函数的信息。多数情况下,这个属性中保存的就是一个函数标识符,或者说一个字符串化的变量名。即使函数没有名称,也会如实显示为空字符串。如果他是使用Function构造函数创建的,则会被标识为“anonymous”
如果函数是一个获取函数、设置函数,或者使用 bind()实例化,那么标识符前面会加上一个前缀:
10.3 理解参数
ECMAScript函数的参数跟大多数其他语言不同。ECMAScript函数既不关心传入的参数个数,也不关心这些参数的数据类型。定义函数时要接收两个参数,并不意味着调用时就要传递两个参数。可以传一个,三个,甚至一个都不传,解释器也不会报错。
之所以会这样,是因为ECMAScript函数的参数在内部表现为一个数组。函数被调用时总会接收一个数组,但函数并不关心这个数组中包含什么。如果数组中什么也没有,那没问题,如果数组中元素超出了要求,那也没问题。事实上,在使用function关键字定义(非箭头)函数时,可以在函数内部访问arguments对象,从中取得传进来的每个参数值。
arguments对象是一个类数组对象(但不是Array的实例),因此可以利用中括号语法访问其中的元素。而要确定传进来多少个参数,可以访问arguments.length属性。
10.4 没有重载
10.5 默认参数值
10.6 参数扩展与收集
10.7 函数声明与函数表达式
10.8 函数作为值
10.9 函数内部
10.9.1 arguments
arguments.callee指向函数
10.9.2 this
10.9.3 caller
10.9.4 new.target
10.10 函数属性与方法
ECMAScript中函数是对象,因此有属性和方法。每个函数都有两个属性:length和prototype.其中,length属性保存函数定义的命名参数的个数,如下例:
1 | function sayName(name) { |
10.12 递归
10.13 尾调用优化
尾调用优化是一项内存管理优化机制,让JavaScript引擎在满足条件时可以重用栈帧。具体来说,类似外部函数的返回值是一个内部函数的返回值的优化非常适合“尾调用”。比如:
1 | function outerFunction() { |
在ES6优化之前,执行这个例子会在内存中发生如下操作。
- 执行到outerFunction函数体,第一个栈帧被推到栈上。
- 执行outerFunction函数体,到return语句。计算返回值必须先计算innnerFunction
- 执行到innerFunction函数体,第二个栈帧被推到栈上
- 执行innerFunctiton函数体,计算其返回值
- 将返回值传回outerFunction,然后outerFunction再返回值
- 将栈帧弹出栈外
在ES6优化之后,执行这个例子会在内存中发生如下操作。
- 执行outerFunction函数体,第一个栈帧被推到栈上。
- 执行outerFunction函数体,到达return语句。为求值返回语句,必须先求值innerFunction。
- 引擎发现把第一个栈帧弹出栈外也没有问题,因为innerFunction的返回值也是outerFunction的返回值
- 弹出outerFunction的栈帧
- 执行到innerFunction函数体,栈帧被推到栈上
- 执行innerFunction函数体,计算其返回值
- 将innerFunction的栈帧弹出栈外
很明显,第一种情况下每多调用一次嵌套函数,就会多增加一个栈帧。而第二种情况下,无论调用多少次嵌套函数,都只有一个栈帧。
10.13.1 尾调用优化的条件
- 代码在严格模式下运行
- 外部函数的返回值是对尾调用函数的调用
- 尾调用函数返回后不需要执行额外的逻辑
- 尾调用函数不是引用外部函数作用域中自由变量的闭包
10.14 闭包
10.15 this对象
10.14 内存泄漏
10.15 立即执行函数表达式IIFE
10.16 私有变量
第11章 Promise与异步函数
本章内容
- 异步编程
- Promise
- 异步函数
11.1 异步编程
11.2 Promise
11.2.1 Promise/A+规范
11.2.2 Promise基础
Promise通过new操作符来实例化。创建Promise时需要传入执行器(executor)函数作为参数。
Promise状态机
拒绝值,拒绝理由及Promise用例
通过执行函数控制Proimse的状态
Promise.resolve()
Proimse.reject()
同步/异步执行的二元性
11.2.3 Promise实例的方法
实现Thenable接口
Promise.prototype.then()
Promise.prototype.catch()
Promise.prototype.finally()
非重入Proimse方法
邻近处理程序的执行顺序
传递解决值和拒绝理由
拒绝Promise与拒绝错误处理
11.2.4 Promise的连锁与Proimse合成
Promise连锁
Promise图
Promise.all()
Promise.race()
11.2.5 Promise扩展
Proimse取消
Promise进度通知
11.3 异步函数
第12章 BOM
本章内容
理解BOM核心,window对象
控制窗口及弹窗
通过location对象获取页面信息
通过navigator对象了解浏览器
通过history对象操作浏览器历史
12.1 window对象
BOM的核心是window对象,代表浏览器实例。window对象在浏览器中有两重身份,一个是ECMAScript中的Global对象,另一个就是浏览器窗口的JavaScript接口。这意味着网页中定义的所有对象,变量和函数都以window作为其Global对象,都可以访问其上定义的parseInt()等全局方法。
12.1.1 Global作用域
12.1.2 窗口关系
top对象始指向最上层(最外层)窗口,即浏览器窗口本身。而parent对象则始终指向当前窗口的父窗口。如果当前窗口是最上层窗口,则parent等于top(都等于window)。最上层的window如果不是通过window.open()打开的,那么其name属性就不会包含值。
self对象,他是终极window属性,始终指向window。实际上,selft就是window。之所以要暴露self,是为了和top,parent一致
12.1.3 窗口位置与像素比
window对象的位置可以通过不同的属性和方法来确定。现在浏览器提供了screenLeft和screeTop属性,用于表示窗口相对于屏幕左侧和顶部的位置,返回值的单位是CSS像素。
可以使用moveTo()和moveBy()方法移动窗口。这两个方法都接受两个参数,其中moveTo()接收要移动到的新位置的绝对坐标x和y。而moveBy()则接收相对当前位置在两个方向上移动的像素数。
devicePixelRatio就是物理像素/逻辑像素
12.1.4 窗口大小
window的属性
- innerHeight
- innerWidth
- outerHeight
- outerWidth
调整大小
- window.resizeTo(width, height)
- window.resizeBy(width, height);
12.1.5 视口位置
度量文档相对于视口滚动距离的属性有两对,返回相等的值
- window.pageXoffset/window.scrollX
- window.pageYoffset/window.scrollY
可以使用scroll(),scrollTo()和scrollBy()方法滚动页面。
1 | // 相对于当前视口向下滚动 100 像素 |
这几个方法也都接收一个 ScrollToOptions字典,除了提供偏移值,还可以通过 behavior属性告诉浏览器是否平滑滚动。
1 | // 正常滚动 |
12.1.6 导航与打开新窗口
window.open()方法可以用于导航到制定的URL,也可以用于打开新浏览器窗口。
`window.open(targetURL, targetWindow, specialString, isReplaced).
这个方法接收 4
个参数:要加载的 URL、目标窗口、特性字符串和表示新窗口在浏览器历史记录中是否替代当前加载页面的布尔值。通常,调用这个方法时只传前 3 个参数,最后一个参数只有在不打开新窗口时才会使用。
如果 window.open()的第二个参数是一个已经存在的窗口或窗格(frame)的名字,则会在对应的窗口或窗格中打开 URL。下面是一个例子:
1 | // 与<a href="http://www.wrox.com" target="topFrame"/>相同 |
执行这行代码的结果就如同用户点击了一个 href 属性为”http://www.wrox.com",target 属性为”topFrame”的链接。如果有一个窗口名叫”topFrame”,则这个窗口就会打开这个 URL;否则就会打开一个新窗口并将其命名为”topFrame”。第二个参数也可以是一个特殊的窗口名,比如_self、_parent、_top或_blank。
- 弹出窗口
如果 window.open()的第二个参数不是已有窗口,则会打开一个新窗口或标签页。第三个参数,即特性字符串,用于指定新窗口的配置。如果没有传第三个参数,则新窗口(或标签页)会带有所有默认的浏览器特性(工具栏、地址栏、状态栏等都是默认配置)。如果打开的不是新窗口,则忽略第三个参数。
特性字符串是一个逗号分隔的设置字符串,用于指定新窗口包含的特性。下表列出了一些选项。
window.open()方法返回一个对新建窗口的引用。这个对象与普通 window对象没有区别,只是为控制新窗口提供了方便。例如,某些浏览器默认不允许缩放或移动主窗口,但可能允许缩放或移动通过window.open()创建的窗口。跟使用任何 window 对象一样,可以使用这个对象操纵新打开的窗口。
1 | let wroxWin = window.open("http://www.wrox.com/", |
还可以使用 close()方法像这样关闭新打开的窗口:
1 | wroxWin.close(); |
这个方法只能用于 window.open()创建的弹出窗口。虽然不可能不经用户确认就关闭主窗口,但弹出窗口可以调用 top.close()来关闭自己。关闭窗口以后,窗口的引用虽然还在,但只能用于检查其 closed 属性了:
1 | wroxWin.close(); |
新创建窗口的 window 对象有一个属性 opener,指向打开它的窗口。这个属性只在弹出窗口的最上层 window 对象(top)有定义,是指向调用 window.open()打开它的窗口或窗格的指针。例如:
1 | let wroxWin = window.open("http://www.wrox.com/", |
虽然新建窗口中有指向打开它的窗口的指针,但反之则不然。窗口不会跟踪记录自己打开的新窗口,因此开发者需要自己记录。
在某些浏览器中,每个标签页会运行在独立的进程中。如果一个标签页打开了另一个,而 window对象需要跟另一个标签页通信,那么标签便不能运行在独立的进程中。在这些浏览器中,可以将新打开的标签页的 opener属性设置为 null,表示新打开的标签页可以运行在独立的进程中。比如:
1 | let wroxWin = window.open("http://www.wrox.com/", |
把 opener 设置为 null 表示新打开的标签页不需要与打开它的标签页通信,因此可以在独立进程中运行。这个连接一旦切断,就无法恢复了。
安全限制
弹窗屏蔽程序
12.1.7 定时器
所有setTimeout的回调函数都会在全局作用域中的一个匿名函数中运行,因此函数中的this值在非严格模式下始终指向window,而在严格模式下是undefined。如果给setTimeout()提供了一个箭头函数,那么this将会保留为定义它时所在的词法作用域。
这里的关键点是,第二个参数,也就是间隔时间,指的是向队列添加新任务之前等待的时间。比如,调用 setInterval()的时间为 01:00:00,间隔时间为 3000 毫秒。这意
味着 01:00:03 时,浏览器会把任务添加到执行队列。浏览器不关心这个任务什么时候执行或者执行要花多长时间。因此,到了 01:00:06,它会再向队列中添加一个任务。由此可看
出,执行时间短、非阻塞的回调函数比较适合 setInterval()。
12.1.8 系统对话框
使用alert(), confirm()和prompt()方法,可以让浏览器调用系统对话框向用户显示信息。这些对话框与浏览器中显示的网页无关,而且也不包含HTML。他们的外观由操作系统或者是浏览器来决定,无法使用CSS设置。此外,这些对话框都是同步的模态对话框,即在显示他们的时候,代码会停止执行,在他们消失后,代码才恢复运行。
alert()方法在本书示例中经常用到。它接收一个要显示给用户的字符串。与 console.log 可以接收任意数量的参数且能一次性打印这些参数不同, alert()只接收一个参数。调用 alert()时,传入的字符串会显示在一个系统对话框中。对话框只有一个“OK” (确定)按钮。如果传给 alert()的参数不是一个原始字符串,则会调用这个值的 toString()方法将其转换为字符串。
警告框(alert)通常用于向用户显示一些他们无法控制的消息,比如报错。用户唯一的选择就是在看到警告框之后把它关闭。图 12-1 展示了一个警告框。
第二种对话框叫确认框,通过调用 confirm()来显示。确认框跟警告框类似,都会向用户显示消息。但不同之处在于,确认框有两个按钮:“Cancel” (取消)和“OK”(确定)。用户通过单击不同的按钮表明希望接下来执行什么操作。比如,confirm(“Are you sure?”)会显示图 12-2 所示的确认框。
1 | if (confirm("Are you sure?")) { |
在这个例子中,第一行代码向用户显示了确认框,也就是 if语句的条件。如果用户单击了 OK 按钮,则会弹出警告框显示”I’m so glad you’re sure!”。如果单击了 Cancel,则会显示”I’m sorry tohear you’re not sure.”。确认框通常用于让用户确认执行某个操作,比如删除邮件等。因为这种对话框会完全打断正在浏览网页的用户,所以应该在必要时再使用。
最后一种对话框是提示框,通过调用 prompt()方法来显示。提示框的用途是提示用户输入消息。除了 OK 和 Cancel 按钮,提示框还会显示一个文本框,让用户输入内容。 prompt()方法接收两个参数:要显示给用户的文本,以及文本框的默认值(可以是空字符串)。调用 prompt(“What is your name?”,”Jake”)会显示图 12-3 所示的提示框。
如果用户单击了 OK 按钮,则 prompt()会返回文本框中的值。如果用户单击了 Cancel 按钮,或者对话框被关闭,则 prompt()会返回 null。下面是一个例子:
1 | let result = prompt("What is your name? ", ""); |
这些系统对话框可以向用户显示消息、确认操作和获取输入。由于不需要 HTML 和 CSS,所以系统对话框是 Web 应用程序最简单快捷的沟通手段。
很多浏览器针对这些系统对话框添加了特殊功能。如果网页中的脚本生成了两个或更多系统对话框,则除第一个之外所有后续的对话框上都会显示一个复选框,如果用户选中则会禁用后续的弹框,直到页面刷新。
如果用户选中了复选框并关闭了对话框,在页面刷新之前,所有系统对话框(警告框、确认框、提示框)都会被屏蔽。开发者无法获悉这些对话框是否显示了。对话框计数器会在浏览器空闲时重置,因此如果两次独立的用户操作分别产生了两个警告框,则两个警告框上都不会显示屏蔽复选框。如果一次独立的用户操作连续产生了两个警告框,则第二个警告框会显示复选框。
JavaScript 还可以显示另外两种对话框:find()和 print()。这两种对话框都是异步显示的,即控制权会立即返回给脚本。用户在浏览器菜单上选择“查找” (find)和“打印” (print)时显示的就是这两种对话框。通过在 window对象上调用 find()和 print()可以显示它们,比如:
1 | // 显示打印对话框 |
这两个方法不会返回任何有关用户在对话框中执行了什么操作的信息,因此很难加以利用。此外,
因为这两种对话框是异步的,所以浏览器的对话框计数器不会涉及它们,而且用户选择禁用对话框对它
们也没有影响。
12.2 location对象
location是最有用的BOM对象之一,提供了当前窗口中加载文档的信息,以及通常的导航功能。
这个对象独特的地方在于,它既是window的属性,也是document的属性。也就是说window.location和document.location指向同一个对象。location对象不仅保存着当前加载文档的信息,也保存着把URL解析为离散片段后能够通过属性访问的信息。这些解析后的属性在下表中有详细的说明(location前缀是必须的).
假设浏览器当前加载的URL是http://foouser:barpassword@www.wrox.com:80/WileyCDA/?q=javascript#contents,location对象的内容如下表所示。

12.2.1 查询字符串
location 的多数信息都可以通过上面的属性获取。但是 URL 中的查询字符串并不容易使用。虽然location.search返回了从问号开始直到 URL 末尾的所有内容,但没有办法逐个访问每个查询参数。下面的函数解析了查询字符串,并返回一个以每个查询参数为属性的对象:
1 | let getQueryStringArgs = function() { |
这个函数首先删除了查询字符串开头的问号,当然前提是 location.search必须有内容。解析后的参数将被保存到 args 对象,这个对象以字面量形式创建。接着,先把查询字符串按照&分割成数组,每个元素的形式为 name=value。for 循环迭代这个数组,将每一个元素按照=分割成数组,这个数组第一项是参数名,第二项是参数值。参数名和参数值在使用 decodeURIComponent()解码后(这是因为查询字符串通常是被编码后的格式)分别保存在 name和 value 变量中。最后,name 作为属性而 value
作为该属性的值被添加到 args对象。这个函数可以像下面这样使用:
1 | // 假设查询字符串为?q=javascript&num=10 |
URLSearchParams
URLSearchParams 提供了一组标准 API 方法,通过它们可以检查和修改查询字符串。给URLSearchParams 构造函数传入一个查询字符串,就可以创建一个实例。这个实例上暴露了 get()、set()和 delete()等方法,可以对查询字符串执行相应操作。下面来看一个例子:
1 | let qs = "?q=javascript&num=10"; |
大多数支持 URLSearchParams的浏览器也支持将 URLSearchParams的实例用作可迭代对象:
1 | let qs = "?q=javascript&num=10"; |
12.2.2 操作地址
可以通过修改 location 对象修改浏览器的地址。首先,最常见的是使用 assign()方法并传入一个 URL,如下所示:
1 | location.assign("http://www.wrox.com"); |
这行代码会立即启动导航到新 URL 的操作,同时在浏览器历史记录中增加一条记录。如果给location.href 或 window.location 设置一个 URL,也会以同一个 URL 值调用 assign()方法。比如,下面两行代码都会执行与显式调用 assign()一样的操作:
1 | window.location = "http://www.wrox.com"; |
在这 3 种修改浏览器地址的方法中,设置 location.href 是最常见的。修改 location对象的属性也会修改当前加载的页面。其中, hash、 search、 hostname、 pathname
和 port属性被设置为新值之后都会修改当前 URL,如下面的例子所示:
1 | // 假设当前 URL 为 http://www.wrox.com/WileyCDA/ |
除了 hash 之外,只要修改 location 的一个属性,就会导致页面重新加载新 URL。
在以前面提到的方式修改 URL 之后,浏览器历史记录中就会增加相应的记录。当用户单击“后退”按钮时,就会导航到前一个页面。如果不希望增加历史记录,可以使用 replace()方法。这个方法接收一个 URL 参数,但重新加载后不会增加历史记录。调用 replace()之后,用户不能回到前一页。比如下面的例子:
1 |
|
浏览器加载这个页面 1 秒之后会重定向到 www.wrox.com。此时,“后退”按钮是禁用状态,即不能返回这个示例页面,除非手动输入完整的 URL。
最后一个修改地址的方法是 reload(),它能重新加载当前显示的页面。调用 reload()而不传参数,页面会以最有效的方式重新加载。也就是说,如果页面自上次请求以来没有修改过,浏览器可能会从缓存中加载页面。如果想强制从服务器重新加载,可以像下面这样给 reload()传个 true:
1 | location.reload(); // 重新加载,可能是从缓存加载 |
脚本中位于 reload()调用之后的代码可能执行也可能不执行,这取决于网络延迟和系统资源等因素。为此,最好把 reload()作为最后一行代码。
12.3 navigator对象
navigator 是由 Netscape Navigator 2 最早引入浏览器的,现在已经成为客户端标识浏览器的标准。只要浏览器启用 JavaScript,navigator 对象就一定存在。但是与其他 BOM 对象一样,每个浏览器都支持自己的属性。
navigator 对 象 实 现 了 NavigatorID、 NavigatorLanguage、 NavigatorOnLine、NavigatorContentUtils、 NavigatorStorage、 NavigatorStorageUtils、 Navigator-ConcurrentHardware、NavigatorPlugins和 NavigatorUserMedia 接口定义的属性和方法。
下表列出了这些接口定义的属性和方法:


12.3.1 检测插件
检测浏览器是否安装了某个插件是开发中常见的需求。除 IE10 及更低版本外的浏览器,都可以通过 plugins数组来确定。这个数组中的每一项都包含如下属性。
- name: 插件名称
- description: 插件介绍
- filename: 插件的文件名
- length: 由当前插件处理的MIME类型数量
plugins 数组中的每个插件对象还有一个 MimeType对象,可以通过中括号访问。
每个 MimeType 对象有 4 个属性:description 描述 MIME 类型,enabledPlugin 是
指向插件对象的指针, suffixes是该 MIME 类型对应扩展名的逗号分隔的字符串, type
是完整的 MIME 类型字符串。
12.3.2 注册处理程序
现代浏览器支持 navigator 上的(在 HTML5 中定义的)registerProtocolHandler()方法。
这个方法可以把一个网站注册为处理某种特定类型信息应用程序。随着在线 RSS 阅读器和电子邮件客户端的流行,可以借助这个方法将 Web 应用程序注册为像桌面软件一样的默认应用程序。
要使用 registerProtocolHandler()方法,必须传入 3 个参数:要处理的协议(如”mailto”或”ftp”)、处理该协议的 URL,以及应用名称。比如,要把一个 Web 应用程序注册为默认邮件客户端,可以这样做:
1 | navigator.registerProtocolHandler("mailto", |
这个例子为”mailto”协议注册了一个处理程序,这样邮件地址就可以通过指定的 Web 应用程序打开。注意,第二个参数是负责处理请求的 URL,%s表示原始的请求。
12.4 screen对象
window 的另一个属性 screen对象,是为数不多的几个在编程中很少用的 JavaScript 对象。这个对象中保存的纯粹是客户端能力信息,也就是浏览器窗口外面的客户端显示器的信息,比如像素宽度和像素高度。每个浏览器都会在 screen 对象上暴露不同的属性。下表总结了这些属性。

12.5 history对象
history 对象表示当前窗口首次使用以来用户的导航历史记录。因为 history是 window 的属性,所以每个 window 都有自己的 history 对象。出于安全考虑,这个对象不会暴露用户访问过的 URL,但可以通过它在不知道实际 URL 的情况下前进和后退。
12.5.1 导航
go()方法可以在用户历史记录中沿任何方向导航,可以前进也可以后退。这个方法只接收一个参数,这个参数可以是一个整数,表示前进或后退多少步。负值表示在历史记录中后退(类似点击浏览器的“后退”按钮),而正值表示在历史记录中前进(类似点击浏览器的“前进”按钮)。下面来看几个例子:
1 | // 后退一页 |
go()有两个简写方法:back()和 forward()。顾名思义,这两个方法模拟了浏览器的后退按钮和前进按钮:
1 | // 后退一页 |
history对象还有一个 length属性,表示历史记录中有多个条目。这个属性反映了历史记录的数量,包括可以前进和后退的页面。对于窗口或标签页中加载的第一个页面,history.length等于 1。通过以下方法测试这个值,可以确定用户浏览器的起点是不是你的页面:
1 | if (history.length == 1){ |
history对象通常被用于创建“后退”和“前进”按钮,以及确定页面是不是用户历史记录中的第一条记录。
注意 如果页面 URL 发生变化,则会在历史记录中生成一个新条目。对于 2009 年以来发
布的主流浏览器,这包括改变 URL 的散列值(因此,把 location.hash 设置为一个新
值会在这些浏览器的历史记录中增加一条记录) 。这个行为常被单页应用程序框架用来模
拟前进和后退,这样做是为了不会因导航而触发页面刷新。
12.5.2 历史状态管理
现代 Web 应用程序开发中最难的环节之一就是历史记录管理。用户每次点击都会触发页面刷新的时代早已过去,“后退”和“前进”按钮对用户来说就代表“帮我切换一个状态”的历史也就随之结束
了。为解决这个问题,首先出现的是 hashchange 事件(第 17 章介绍事件时会讨论)。HTML5 也为history对象增加了方便的状态管理特性。
hashchange 会在页面 URL 的散列变化时被触发,开发者可以在此时执行某些操作。而状态管理API 则可以让开发者改变浏览器 URL 而不会加载新页面。为此,可以使用 history.pushState()方法。这个方法接收 3 个参数:一个 state对象、一个新状态的标题和一个(可选的)相对 URL。例如:
1 | let stateObject = {foo: "bar"}; |
pushState()方法执行后,状态信息就会被推到历史记录中,浏览器地址栏也会改变以反映新的相对 URL。除了这些变化之外,即使 location.href返回的是地址栏中的内容,浏览器页不会向服务器发送请求。第二个参数并未被当前实现所使用,因此既可以传一个空字符串也可以传一个短标题。第一个参数应该包含正确初始化页面状态所必需的信息。为防止滥用,这个状态的对象大小是有限制的,通常在 500KB~1MB 以内。
因为 pushState()会创建新的历史记录,所以也会相应地启用“后退”按钮。此时单击“后退”按钮,就会触发 window对象上的 popstate事件。 popstate事件的事件对象有一个 state属性,其中包含通过 pushState()第一个参数传入的 state对象:
1 | window.addEventListener("popstate", (event) => { |
基于这个状态,应该把页面重置为状态对象所表示的状态(因为浏览器不会自动为你做这些) 。记住,页面初次加载时没有状态。因此点击“后退”按钮直到返回最初页面时, event.state会为 null。可以通过 history.state 获取当前的状态对象,也可以使用 replaceState()并传入 与pushState()同样的前两个参数来更新状态。更新状态不会创建新历史记录,只会覆盖当前状态:
1 | history.replaceState({newFoo: "newBar"}, "New title"); |
传给 pushState()和 replaceState()的 state 对象应该只包含可以被序列化的信息。因此,DOM 元素之类并不适合放到状态对象里保存。
使用 HTML5 状态管理时,要确保通过 pushState()创建的每个“假”URL 背后
都对应着服务器上一个真实的物理 URL。否则,单击“刷新”按钮会导致 404 错误。所有
单页应用程序(SPA,Single Page Application)框架都必须通过服务器或客户端的某些配
置解决这个问题。
第13章 客户端检测
本章内容
- 使用能力检测
- 用户代理检测的历史
- 软件与硬件检测
- 检测策略
虽然浏览器厂商齐心协力想要实现一致的接口,但事实上仍然是每家浏览器都有自己的长处与不足。跨平台的浏览器尽管版本相同,但总会存在不同的问题。这些差异迫使 Web 开发者要么面向最大公约数而设计,要么(更常见地)使用各种方法来检测客户端,以克服或避免这些缺陷。
客户端检测一直是 Web 开发中饱受争议的话题,这些话题普遍围绕所有浏览器应支持一系列公共特性,理想情况下是这样的。而现实当中,浏览器之间的差异和莫名其妙的行为,让客户端检测变成一种补救措施,而且也成为了开发策略的重要一环。如今,浏览器之间的差异相对 IE 大溃败以前已经好很多了,但浏览器间的不一致性依旧是 Web 开发中的常见主题。
要检测当前的浏览器有很多方法,每一种都有各自的长处和不足。问题的关键在于知道客户端检测应该是解决问题的最后一个举措。任何时候,只要有更普适的方案可选,都应该毫不犹豫地选择。首先要设计最常用的方案,然后再考虑为特定的浏览器进行补救。
13.1 能力检测
能力检测(又称特性检测)即在 JavaScript 运行时中使用一套简单的检测逻辑,测试浏览器是否支持某种特性。这种方式不要求事先知道特定浏览器的信息,只需检测自己关心的能力是否存在即可。能力检测的基本模式如下:
1 | if (object.propertyInQuestion) { |
13.1.1 安全能力检测
13.1.2 基于能力检测进行浏览器分析
13.2 用户代理检测
用户代理检测通过浏览器的用户代理字符串确定使用的是什么浏览器。用户代理字符串包含在每个HTTP请求的头部,在JavaScript中可以通过navigator.userAgent访问。在服务端,常见的做法是根据接收到的用户代理字符串确定浏览器并执行相应操作。而在客户端,用户代理检测被认为是不可靠的,只应该在没有其他选项时再考虑。
用户代理字符串最受争议的地方就是,在很长一段时间里,浏览器都通过在用户代理字符串包含错误或误导性信息来欺骗服务器。要理解背后的原因,必须回顾一下自 Web 出现之后用户代理字符串的历史。
13.2.1 用户代理的历史
13.3 软件与硬件检测
现代浏览器提供了一组与页面执行环境相关的信息,包括浏览器、操作系统、硬件和周边设备信息。
这些属性可以通过暴露在 window.navigator 上的一组 API 获得。不过,这些 API 的跨浏览器支持还不够好,远未达到标准化的程度。
13.3.1 识别浏览器和操作系统
特性检测和用户代理字符串解析是当前常用的两种识别浏览器的方式。而 navigator 和 screen对象也提供了关于页面所在软件环境的信息。
13.3.2 浏览器元数据
第14章 DOM
本章内容
- 理解文档对象模型(DOM)的构成
- 节点类型
- 浏览器兼容性
- MutationObserver接口
文档对象模型(DOM, Document Object Model)是HTML和XML文档的编程接口。DOM表示由多层节点构成的文档,通过它开发者可以添加,删除和修改页面的各个部分。
脱胎于网景和微软早期的动态 HTML(DHTML,Dynamic HTML),DOM 现在是真正跨平台、语言无关的表示和操作网页的方式。
DOM Level 1 在 1998 年成为 W3C 推荐标准,提供了基本文档结构和查询的接口。本章之所以介绍DOM,主要因为它与浏览器中的 HTML 网页相关,并且在 JavaScript 中提供了 DOM API。
14.1 节点层级
<html>元素我们称之为文档元素(documentElement).
14.1.1 Node类型
DOM Level1 描述了名为Node的接口,这个接口是所有DOM节点类型都必须实现的。Node接口在JavaScript中被实现为Node类型。JavaScript中,所有节点类型都继承Node类型,因此所有类型都共享相同的基本属性和方法。
每个节点都有nodeType属性,表示该节点的类型。节点类型由定义在Node类型上的12个数值常量表示
- Node.ELEMENT_NODE: 1
- Node.ATTRIBUTE_NODE: 2
- Node.TEXT_NODE: 3
- Node.CDATA_SECTION_NODE: 4
- Node.ENTITY_REFERENCE_NODE: 5
- Node.ENTITY_NODE: 6
- Node.PROCESSING_INSTRUCTION_NODE: 7
- Node.COMMENT_NODE: 8
- Node.DOCUMENT_NODE: 9
- Node.DOCUMENT_TYPE_NODE: 10
- Node.DOCUMENT_FRAGMENT_NODE: 11
- Node.NOTATION_NODE: 12
节点类型可通过与这些常量比较来确定,比如:
1 | if (someNode.nodeType == Node.ELEMENT_NODE){ |
这个例子比较了 someNode.nodeType 与 Node.ELEMENT_NODE 常量。如果两者相等,则意味着someNode 是一个元素节点。
浏览器并不支持所有节点类型。开发者最常用到的是元素节点和文本节点。本章后面会讨论每种节点受支持的程度及其用法。
- nodeName与nodeValue
nodeName 与 nodeValue 保存着有关节点的信息。这两个属性的值完全取决于节点类型。在使用
这两个属性前,最好先检测节点类型,如下所示:
1 | if (someNode.nodeType == 1){ |
在这个例子中,先检查了节点是不是元素。如果是,则将其 nodeName 的值赋给一个变量。对元素而言,nodeName始终等于元素的标签名,而 nodeValue则始终为 null。
- 节点关系
文档中的所有节点都与其他节点有关系。这些关系可以形容为家族关系,相当于把文档树比作家谱。在 HTML 中, <body>元素是<html>元素的子元素,而<html>元素则是<body>元素的父元素。 <head>元素是<body>元素的同胞元素,因为它们有共同的父元素<html>。
每个节点都有一个 childNodes属性,其中包含一个 NodeList的实例。 NodeList是一个类数组对象,用于存储可以按位置存取的有序节点。注意,NodeList并不是 Array 的实例,但可以使用中括号访问它的值,而且它也有 length 属性。NodeList 对象独特的地方在于,它其实是一个对 DOM 结构的查询,因此 DOM 结构的变化会自动地在 NodeList中反映出来。我们通常说 NodeList 是实时的活动对象,而不是第一次访问时所获得内容的快照。(通过document.querySelectorAll()获取的是快照)
下面的例子展示了如何使用中括号或使用 item()方法访问 NodeList中的元素:
1 | let firstChild = someNode.childNodes[0]; |
无论是使用中括号还是 item()方法都是可以的,但多数开发者倾向于使用中括号,因为它是一个类数组对象。注意,length 属性表示那一时刻 NodeList 中节点的数量。使用 Array.prototype.slice()可以像前面介绍 arguments时一样把 NodeList对象转换为数组。比如
1 | let arrayOfNodes = Array.prototype.slice.call(someNode.childNodes,0); |
每个节点都有一个 parentNode 属性,指向其 DOM 树中的父元素。childNodes中的所有节点都有同一个父元素,因此它们的 parentNode属性都指向同一个节点。此外, childNodes列表中的每个节点都是同一列表中其他节点的同胞节点。而使用 previousSibling和 nextSibling 可以在这个列表的节点间导航。这个列表中第一个节点的 previousSibling 属性是 null,最后一个节点的nextSibling 属性也是 null,如下所示:
1 | if (someNode.nextSibling === null){ |
注意,如果 childNodes中只有一个节点,则它的 previousSibling和 nextSibling属性都是null。
父节点和它的第一个及最后一个子节点也有专门属性:firstChild 和 lastChild 分别指向childNodes 中的第一个和最后一个子节点。someNode.firstChild 的值始终等于 someNode.
childNodes[0],而 someNode.lastChild 的值始终等于 someNode.childNodes[someNode.childNodes.length-1]。如果只有一个子节点,则 firstChild和 lastChild指向同一个节点。如果没有子节点,则 firstChild 和 lastChild 都是 null。
上述这些节点之间的关系为在文档树的节点之间导航提供了方便。图 14-2 形象地展示了这些关系。
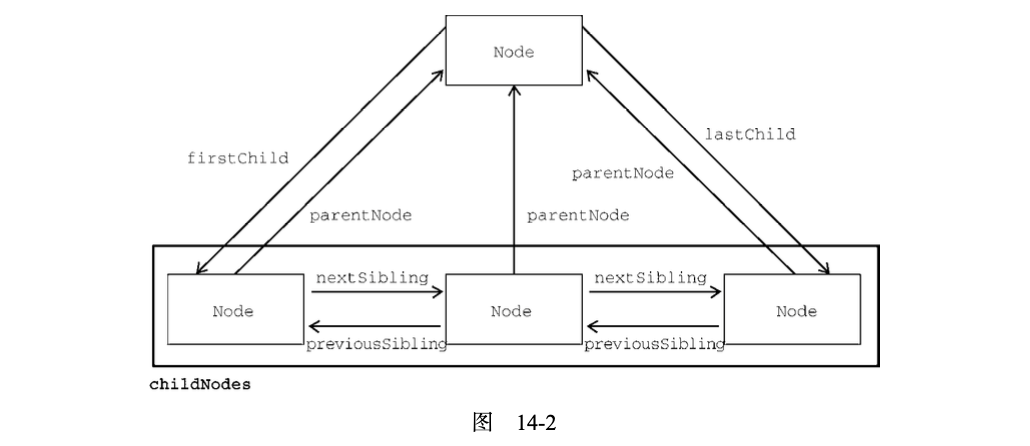
有了这些关系,childNodes属性的作用远远不止是必备属性那么简单了。这是因为利用这些关系指针,几乎可以访问到文档树中的任何节点,而这种便利性是 childNodes的最大亮点。还有一个便利的方法是 hasChildNodes(),这个方法如果返回 true 则说明节点有一个或多个子节点。相比查询childNodes 的 length 属性,这个方法无疑更方便。
最后还有一个所有节点都共享的关系。ownerDocument 属性是一个指向代表整个文档的文档节点的指针。所有节点都被创建它们(或自己所在)的文档所拥有,因为一个节点不可能同时存在于两个或者多个文档中。这个属性为迅速访问文档节点提供了便利,因为无需在文档结构中逐层上溯了。
- 操纵节点
因为所有关系指针都是只读的,所以 DOM 又提供了一些操纵节点的方法。最常用的方法是appendChild(),用于在 childNodes 列表末尾添加节点。添加新节点会更新相关的关系指针,包括
父节点和之前的最后一个子节点。appendChild()方法返回新添加的节点,如下所示:
1 | let returnedNode = someNode.appendChild(newNode); |
如果把文档中已经存在的节点传给 appendChild(),则这个节点会从之前的位置被转移到新位置。即使 DOM 树通过各种关系指针维系,一个节点也不会在文档中同时出现在两个或更多个地方。因此,如果调用 appendChild()传入父元素的第一个子节点,则这个节点会成为父元素的最后一个子节点,如下所示:
1 | // 假设 someNode 有多个子节点 |
如果想把节点放到 childNodes 中的特定位置而不是末尾,则可以使用 insertBefore()方法。这个方法接收两个参数:要插入的节点和参照节点。调用这个方法后,要插入的节点会变成参照节点的前一个同胞节点,并被返回。如果参照节点是 null,则 insertBefore()与 appendChild()效果相同,如下面的例子所示:
1 | // 作为最后一个子节点插入 |
appendChild()和 insertBefore()在 插 入 节 点 时 不 会 删 除 任 何 已 有 节 点 。 相 对 地 ,replaceChild()方法接收两个参数:要插入的节点和要替换的节点。要替换的节点会被返回并从文档树中完全移除,要插入的节点会取而代之。下面看一个例子:
1 | // 替换第一个子节点 |
使用 replaceChild()插入一个节点后,所有关系指针都会从被替换的节点复制过来。虽然被替换的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置。要移除节点而不是替换节点,可以使用 removeChild()方法。这个方法接收一个参数,即要移除的节点。被移除的节点会被返回,如下面的例子所示:
1 | // 删除第一个子节点 |
与 replaceChild()方法一样,通过 removeChild()被移除的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置。上面介绍的 4 个方法都用于操纵某个节点的子元素,也就是说使用它们之前必须先取得父节点(使用前面介绍的 parentNode 属性)。并非所有节点类型都有子节点,如果在不支持子节点的节点上调用这些方法,则会导致抛出错误。
- 其他方法
所有节点类型还共享了两个方法。第一个是 cloneNode(),会返回与调用它的节点一模一样的节点。cloneNode()方法接收一个布尔值参数,表示是否深复制。在传入 true参数时,会进行深复制,即复制节点及其整个子 DOM 树。如果传入 false,则只会复制调用该方法的节点。复制返回的节点属于文档所有,但尚未指定父节点,所以可称为孤儿节点(orphan) 。可以通过 appendChild()、insertBefore()或 replaceChild()方法把孤儿节点添加到文档中。以下面的 HTML 片段为例
1 | <ul> |
如果myList保存着对这个<ul>元素的引用,则下列代码展示了使用cloneNode()方法的两种方式:
1 | let deepList = myList.cloneNode(true); |
cloneNode()方法不会复制添加到 DOM 节点的 JavaScript 属性,比如事件处理程序。这个方法只复制 HTML 属性,以及可选地复制子节点。除此之外则一概不会复制。
IE 在很长时间内会复制事件处理程序,这是一个 bug,所以推荐在复制前先删除事件处理程序。
本节要介绍的最后一个方法是 normalize()。这个方法唯一的任务就是处理文档子树中的文本节点。由于解析器实现的差异或 DOM 操作等原因,可能会出现并不包含文本的文本节点,或者文本节点之间互为同胞关系。在节点上调用 normalize()方法会检测这个节点的所有后代,从中搜索上述两种情形。如果发现空文本节点,则将其删除;如果两个同胞节点是相邻的,则将其合并为一个文本节点。
这个方法将在本章后面进一步讨论。
14.1.2 Document类型
14.1.3 Element类型
HTML元素
取得属性
每个元素都有零个或多个属性,通常用于为元素或其内容附加更多信息。与属性相关的 DOM 方法主要有 3 个:
- getAttribute()
- setAttribute()
- removeAttribute()
这些方法主要用于操纵属性,包括在 HTMLElement类型上定义的属性。下面看一个例子:
1 | let div = document.getElementById("myDiv"); |
注意传给 getAttribute()的属性名与它们实际的属性名是一样的,因此这里要传”class”而非”className” (className是作为对象属性时才那么拼写的) 。 如果给定的属性不存在, 则 getAttribute()返回 null。
getAttribute()方法也能取得不是 HTML 语言正式属性的自定义属性的值。比如下面的元素:
<div id="myDiv" my_special_attribute="hello!"></div>
这个元素有一个自定义属性 my_special_attribute,值为”hello!”。可以像其他属性一样使用getAttribute()取得这个属性的值:let value = div.getAttribute("my_special_attribute");
注意,属性名不区分大小写,因此”ID”和”id”被认为是同一个属性。另外,根据 HTML5 规范的要求,自定义属性名应该前缀 data-以方便验证。
元素的所有属性也可以通过相应 DOM 元素对象的属性来取得。当然,这包括 HTMLElement 上定义的直接映射对应属性的 5 个属性,还有所有公认(非自定义)的属性也会被添加为 DOM 对象的属性。比如下面的例子:
1 | <div id="myDiv" align="left" my_special_attribute="hello"></div> |
因为 id 和 align在 HTML 中是
通过 DOM 对象访问的属性中有两个返回的值跟使用 getAttribute()取得的值不一样。首先是style 属性,这个属性用于为元素设定 CSS 样式。在使用 getAttribute()访问 style 属性时,返回的是 CSS 字符串。而在通过 DOM 对象的属性访问时, style属性返回的是一个(CSSStyleDeclaration)对象。DOM 对象的 style 属性用于以编程方式读写元素样式,因此不会直接映射为元素中 style 属性的字符串值。
第二个属性其实是一类,即事件处理程序(或者事件属性),比如 onclick。在元素上使用事件属性时(比如 onclick),属性的值是一段 JavaScript 代码。如果使用 getAttribute()访问事件属性,则返回的是字符串形式的源代码。而通过 DOM 对象的属性访问事件属性时返回的则是一个 JavaScript函数(未指定该属性则返回 null)。这是因为 onclick及其他事件属性是可以接受函数作为值的。
考虑到以上差异, 开发者在进行 DOM 编程时通常会放弃使用 getAttribute()而只使用对象属性。getAttribute()主要用于取得自定义属性的值。
- 设置属性
- attributes属性
Element 类型是唯一使用 attributes 属性的 DOM 节点类型。attributes 属性包含一个NamedNodeMap 实例,是一个类似 NodeList的“实时”集合。元素的每个属性都表示为一个 Attr节点,并保存在这个 NamedNodeMap 对象中。NamedNodeMap 对象包含下列方法:
- getNamedItem(name), 返回nodeName属性等于name的节点
- removeNamedItem(name), 删除nodeName属性等于name的节点
- setNamedItem(node), 向列表中添加node节点,以其nodeName为索引
- item(pos), 返回索引位置pos处的节点
创建元素
元素后代
14.1.4 Text类型
创建文本节点
规范化文本节点
拆分文本节点
14.1.5 Comment类型
14.1.6 CDATASection类型
14.1.7 DocumentType类型
14.1.8 DocumentFragment类型
在所有节点类型中,DocumentFragment类型是唯一一个在标记中没有对应表示的类型。DOM 将文档 片 段定 义为 “ 轻量 级” 文 档, 能够 包 含和 操作 节 点, 却没 有 完整 文档 那 样额 外的 消 耗 。DocumentFragment 节点具有以下特征:
- nodeType等于11
- nodeName的值为”#document-fragment”;
- nodeValue的值为null
- parentNode的值为null
- 子节点可以是Element,ProcessingInstruction,Comment,Text, CDATASection或EntityReference
不能直接把文档片段添加到文档。相反,文档片段的作用是充当其他要被添加到文档的节点的仓库。可以使用 document.createDocumentFragment()方法像下面这样创建文档片段:
1 | let fragment = document.createDocumentFragment() |
文档片段从 Node 类型继承了所有文档类型具备的可以执行 DOM 操作的方法。如果文档中的一个节点被添加到一个文档片段,则该节点会从文档树中移除,不会再被浏览器渲染。添加到文档片段的新节点同样不属于文档树,不会被浏览器渲染。可以通过 appendChild()或 insertBefore()方法将文档片段的内容添加到文档。在把文档片段作为参数传给这些方法时,这个文档片段的所有子节点会被添加到文档中相应的位置。文档片段本身永远不会被添加到文档树。以下面的 HTML 为例:
1 | <ul id="myList"></ul> |
假设想给这个<ul>元素添加 3 个列表项。如果分 3 次给这个元素添加列表项,浏览器就要重新渲染3 次页面,以反映新添加的内容。为避免多次渲染,下面的代码示例使用文档片段创建了所有列表项,然后一次性将它们添加到了<ul>元素:
1 | let fragment = document.createDocumentFragment(); |
这个例子先创建了一个文档片段,然后取得了<ul>元素的引用。接着通过 for 循环创建了 3 个列表项,每一项都包含表明自己身份的文本。为此先创建<li>元素,再创建文本节点并添加到该元素。然后通过 appendChild()把<li>元素添加到文档片段。循环结束后,通过把文档片段传给 appendChild()将所有列表项添加到了<ul>元素。此时,文档片段的子节点全部被转移到了<ul>元素。
14.1.9 Attr类型
14.2 DOM编程
14.2.1 动态脚本
14.2.2 动态样式
14.2.3 操作表格
14.2.4 使用NodeList
14.3 MotationObserver接口
14.3.1 基本用法
MutationObserver的实例要通过调用 MutationObserver构造函数并传入一个回调函数来创建:
1 | let observer = new MutationObserver(() => console.log('DOM was mutated!')); |
- observe()方法
新创建的MutationObserver实例不会关联DOM的任何部分。要把这个observer与DOM关联起来,需要使用observe()方法。这个方法接收两个必需的参数:要观察变化的DOM节点,以及一个MutationObserverInit对象。
MutationObserverInit对象用于控制观察的是哪些方面的变化,是一个键值对形式配置选项的字典。例如下面的代码会创建一个观察者(observer)并配置它观察<body>元素上的属性变化。
1 | let observer = new MutationObserver(() => console.log('<body> attributes changed')); |
执行以上代码后,
元素上任何属性发生变化都会被这个 MutationObserver实例发现,然后就会异步执行注册的回调函数。元素后代的修改或其他非属性修改都不会触发回调进入任务队列。可以通过以下代码来验证:1 | let observer = new MutationObserver(() => console.log('<body> attributes changed')); |
注意,回调中的 console.log()是后执行的。这表明回调并非与实际的 DOM 变化同步执行。
- 回调与MutationRecord
每个回调都会收到一个 MutationRecord 实例的数组。MutationRecord 实例包含的信息包括发生了什么变化,以及 DOM 的哪一部分受到了影响。因为回调执行之前可能同时发生多个满足观察条件的事件,所以每次执行回调都会传入一个包含按顺序入队的 MutationRecord实例的数组。
下面展示了反映一个属性变化的 MutationRecord 实例的数组:
下面展示了反映一个属性变化的 MutationRecord 实例的数组:
1 | let observer = new MutationObserver( |
下面是一次涉及命名空间的类似变化:
1 | let observer = new MutationObserver( |
连续修改会生成多个 MutationRecord实例,下次回调执行时就会收到包含所有这些实例的数组,顺序为变化事件发生的顺序:
1 | let observer = new MutationObserver( |
下表列出了 MutationRecord实例的属性。


传给回调函数的第二个参数是观察变化的 MutationObserver的实例,演示如下:
1 | let observer = new MutationObserver( |
- disconnect() 方法
默认情况下,只要被观察的元素不被垃圾回收, MutationObserver的回调就会响应 DOM 变化事件,从而被执行。要提前终止执行回调,可以调用 disconnect()方法。下面的例子演示了同步调用disconnect()之后,不仅会停止此后变化事件的回调,也会抛弃已经加入任务队列要异步执行的回调:
1 | let observer = new MutationObserver(() => console.log('<body> attributes changed')); |
要想让已经加入任务队列的回调执行,可以使用 setTimeout()让已经入列的回调执行完毕再调用disconnect():
1 | let observer = new MutationObserver(() => console.log('<body> attributes changed')); |
- 复用MutationObserver
多次调用 observe()方法,可以复用一个 MutationObserver 对象观察多个不同的目标节点。此时, MutationRecord的 target 属性可以标识发生变化事件的目标节点。下面的示例演示了这个过程:
1 | let observer = new MutationObserver( |
disconnect()方法是一个“一刀切”的方案,调用它会停止观察所有目标:
1 | let observer = new MutationObserver( |
- 重用MutationObserver
调用 disconnect()并不会结束 MutationObserver 的生命。还可以重新使用这个观察者,再将它关联到新的目标节点。下面的示例在两个连续的异步块中先断开然后又恢复了观察者与<body>元素的关联:
1 | let observer = new MutationObserver(() => console.log('<body> attributes |
14.3.2 MutationObserverInit与观察范围
MutationObserverInit 对象用于控制对目标节点的观察范围。粗略地讲,观察者可以观察的事件包括属性变化、文本变化和子节点变化。
下表列出了 MutationObserverInit对象的属性。


注意 在调用 observe()时,MutationObserverInit对象中的 attribute、characterData
和 childList 属性必须至少有一项为 true(无论是直接设置这几个属性,还是通过设置
attributeOldValue 等属性间接导致它们的值转换为 true)。否则会抛出错误,因为没
有任何变化事件可能触发回调。
第15章 DOM扩展
本章内容
- 理解Selectors API
- 使用HTML5 DOM扩展
15.1 SelectorsAPI
15.2 querySelectorAll
15.3 HTML5
15.3.1 CSS类扩展
- getElementsByClassName()
15.3.2 焦点管理
15.3.3 HTMLDocument扩展
- readyState属性
document.readyState属性有两个可能的值
- loading: 表示文档正在加载
- complete: 表示文档加载完成
实际开发中,最好是把 document.readyState当成一个指示器,以判断文档是否加载完毕。在这个属性得到广泛支持以前,通常要依赖 onload事件处理程序设置一个标记,表示文档加载完了。这个属性的基本用法如下:
1 | if (document.readyState == "complete"){ |
15.3.6 插入标记
15.3.7 scrollIntoView()
DOM规范中没有设计的一个问题是如何滚动页面中的某个区域。为填充这方面的缺失,不同浏览器实现了不同的控制滚动方式。HTML5标准化了scrollIntoView()
scrollIntoView()方法存在于所有 HTML 元素上,可以滚动浏览器窗口或容器元素以便包含元素进入视口。这个方法的参数如下:
- alignToTop 是一个布尔值
- true:窗口滚动后元素的顶部与视口顶部对齐
- false:窗口滚动后元素的底部与视口底部对齐
- scrollIntoViewOptions是一个选项对象
- behavior: 定义过渡动画,可取的值有”smooth”和”auto”,默认为”auto”
- block: 定义垂直方向的对齐,可取的值为”start”,”center”,”end”和”nearest”,默认为”start”
- inline: 定义水平方向的对齐,可取的值为”start”, “center”, “end”和”nearest”,默认为”nearest”
不传参数等同于alignToTop为true.
1 | // 确保元素可见 |
第16章 DOM2和DOM3
本章内容
- DOM2到DOM3的变化
- 操作样式的DOMAPI
- DOM遍历与范围
第17章 事件
本章内容
- 理解事件流
- 使用事件处理程序
- 了解不同类型的事件
17.1 事件流
17.1.1 事件冒泡
17.1.2 事件捕获
17.1.3 DOM事件流
17.2 事件处理程序
事件意味着用户或浏览器执行的某种动作。比如,单击(click) 、加载(load) 、鼠标悬停(mouseover) 。为响应事件而调用的函数被称为事件处理程序(或事件监听器) 。事件处理程序的名字以”on”开头,因此 click 事件的处理程序叫作 onclick,而 load 事件的处理程序叫作 onload。有很多方式可以指定事件处理程序。
17.2.1 HTML事件处理程序
17.2.2 DOM0事件处理程序
17.2.3 DOM2事件处理程序
DOM2 Events 为事件处理程序的赋值和移除定义了两个方法:addEventListener()和 remove-EventListener()。这两个方法暴露在所有 DOM 节点上,它们接收 3 个参数:事件名、事件处理函数和一个布尔值,true 表示在捕获阶段调用事件处理程序,false(默认值)表示在冒泡阶段调用事件处理程序。
17.3 事件对象
在 DOM 中发生事件时,所有相关信息都会被收集并存储在一个名为 event的对象中。这个对象包含了一些基本信息,比如导致事件的元素、发生的事件类型,以及可能与特定事件相关的任何其他数据。例如,鼠标操作导致的事件会生成鼠标位置信息,而键盘操作导致的事件会生成与被按下的键有关的信息。所有浏览器都支持这个 event 对象,尽管支持方式不同。
17.3.1 DOM事件对象
在 DOM 合规的浏览器中,event 对象是传给事件处理程序的唯一参数。不管以哪种方式(DOM0或 DOM2)指定事件处理程序,都会传入这个 event 对象。下面的例子展示了在两种方式下都可以使用事件对象:
1 | let btn = document.getElementById("myBtn"); |
这个例子中的两个事件处理程序都会在控制台打出 event.type属性包含的事件类型。这个属性中始终包含被触发事件的类型,如”click” (与传给 addEventListener()和 removeEventListener()方法的事件名一致)。在通过 HTML 属性指定的事件处理程序中,同样可以使用变量 event 引用事件对象。下面的例子中演示了如何使用这个变量:
1 | <input type="button" value="Click Me" onclick="console.log(event.type)"> |
以这种方式提供 event 对象,可以让 HTML 属性中的代码实现与 JavaScript 函数同样的功能。如前所述,事件对象包含与特定事件相关的属性和方法。不同的事件生成的事件对象也会包含不同的属性和方法。不过,所有事件对象都会包含下表列出的这些公共属性和方法。

在事件处理程序内部,this 对象始终等于 currentTarget 的值,而 target 只包含事件的实际目标。如果事件处理程序直接添加在了意图的目标,则 this、 currentTarget 和 target的值是一样的。下面的例子展示了这两个属性都等于 this 的情形:
1 | let btn = document.getElementById("myBtn"); |
上面的代码检测了 currentTarget 和 target的值是否等于 this。因为 click 事件的目标是按钮,所以这 3 个值是相等的。如果这个事件处理程序是添加到按钮的父节点(如 document.body)上,那么它们的值就不一样了。比如下面的例子在 document.body上添加了单击处理程序:
1 | document.body.onclick = function(event) { |
这种情况下点击按钮, this 和 currentTarget都等于 document.body,这是因为它是注册事件处理程序的元素。而 target 属性等于按钮本身,这是因为那才是 click 事件真正的目标。由于按钮本身并没有注册事件处理程序,因此 click事件冒泡到 document.body,从而触发了在它上面注册的处理程序。
type 属性在一个处理程序处理多个事件时很有用。比如下面的处理程序中就使用了 event.type:
1 | let btn = document.getElementById("myBtn"); |
在这个例子中,函数 handler 被用于处理 3 种不同的事件:click、mouseover 和 mouseout。当按钮被点击时,应该在控制台打印一条消息,如前面的例子所示。而把鼠标放到按钮上,会导致按钮背景变成红色,接着把鼠标从按钮上移开,背景颜色应该又恢复成默认值。这个函数使用 event.type属性确定了事件类型,从而可以做出不同的响应。
preventDefault()方法用于阻止特定事件的默认动作。比如,链接的默认行为就是在被单击时导航到 href 属性指定的 URL。如果想阻止这个导航行为,可以在 onclick 事件处理程序中取消,如下面的例子所示:
1 | let link = document.getElementById("myLink"); |
任何可以通过 preventDefault()取消默认行为的事件,其事件对象的 cancelable 属性都会设置为 true.
stopPropagation()方法用于立即阻止事件流在 DOM 结构中传播,取消后续的事件捕获或冒泡。例如,直接添加到按钮的事件处理程序中调用 stopPropagation(),可以阻止 document.body上注册的事件处理程序执行。比如:
1 | let btn = document.getElementById("myBtn"); |
如果这个例子中不调用 stopPropagation(),那么点击按钮就会打印两条消息。但这里由于 click事件不会传播到 document.body,因此 onclick事件处理程序永远不会执行。
eventPhase 属性可用于确定事件流当前所处的阶段。如果事件处理程序在捕获阶段被调用,则eventPhase 等于 1;如果事件处理程序在目标上被调用,则 eventPhase 等于 2;如果事件处理程序在冒泡阶段被调用,则 eventPhase等于 3。不过要注意的是,虽然“到达目标”是在冒泡阶段发生的,但其 eventPhase仍然等于 2。下面的例子展示了 eventPhase在不同阶段的值:
1 | let btn = document.getElementById("myBtn"); |
在这个例子中,点击按钮首先会触发注册在捕获阶段的 document.body 上的事件处理程序,显示 eventPhase 为 1。接着,会触发按钮本身的事件处理程序(尽管是注册在冒泡阶段),此时显
示 eventPhase 等于 2。最后触发的是注册在冒泡阶段的 document.body 上的事件处理程序,显示eventPhase 为 3。而当 eventPhase等于 2 时,this、target和 currentTarget 三者相等。
event对象只在事件处理程序执行期间存在,一旦执行完毕,就会被销毁。
17.4 事件类型
DOM3 Events定义了如下数据类型
- 用户界面事件(UIEvent): 设计与BOM交互的通用浏览器事件
- 焦点事件(FocusEvent): 在元素获得和失去焦点时触发
- 鼠标事件(MouseEvent): 使用鼠标在页面上执行某些操作时触发
- 滚轮事件(WheelEvent): 使用鼠标滚轮(或类似设备)时触发。
- 输入事件(InputEvent): 向文档中输入文本时触发
- 键盘事件(KeyboardEvent): 使用键盘在页面上执行某些操作时触发。
- 合成事件(CompositionEvent): 在使用某种IME(Input Method Editor, 输入法编辑器)输入字符时触发。
17.4.7 HTML5事件
contextmenu事件
beforeunload事件
DomContentLoaded事件
window 的 load 事件会在页面完全加载后触发,因为要等待很多外部资源加载完成,所以会花费较长时间。而 DOMContentLoaded 事件会在 DOM 树构建完成后立即触发,而不用等待图片、 JavaScript文件、 CSS 文件或其他资源加载完成。相对于 load事件, DOMContentLoaded可以让开发者在外部资源下载的同时就能指定事件处理程序,从而让用户能够更快地与页面交互。
要处理 DOMContentLoaded 事件,需要给 document 或 window 添加事件处理程序(实际的事件目标是 document,但会冒泡到 window)。下面是一个在 document 上监听 DOMContentLoaded 事件的例子:
1 | document.addEventListener("DOMContentLoaded", (event) => { |
DOMContentLoaded 事件的 event对象中不包含任何额外信息(除了 target 等于 document)。DOMContentLoaded事件通常用于添加事件处理程序或执行其他 DOM 操作。这个事件始终在 load事件之前触发。对于不支持 DOMContentLoaded 事件的浏览器,可以使用超时为 0 的 setTimeout()函数,通过其回调来设置事件处理程序,比如:
readystatechange事件
pageshow与pagehide事件
Firefox 和 Opera 开发了一个名为往返缓存(bfcache,back-forward cache)的功能,此功能旨在使用浏览器“前进”和“后退”按钮时加快页面之间的切换。这个缓存不仅存储页面数据,也存储 DOM 和JavaScript 状态,实际上是把整个页面都保存在内存里。如果页面在缓存中,那么导航到这个页面时就不会触发 load 事件。通常,这不会导致什么问题,因为整个页面状态都被保存起来了。不过,Firefx决定提供一些事件,把往返缓存的行为暴露出来。
第一个事件是 pageshow,其会在页面显示时触发,无论是否来自往返缓存。在新加载的页面上,pageshow 会在 load 事件之后触发;在来自往返缓存的页面上,pageshow 会在页面状态完全恢复后触发。注意,虽然这个事件的目标是 document,但事件处理程序必须添加到 window 上。下面的例子展示了追踪这些事件的代码:
- hashchange事件
17.4.8 设备事件
17.5 内存与性能
17.5.1 事件委托
17.5.2 删除事件处理程序
第18章 动画与Canvas
本章内容
- 使用requestAnimationFrame
- 理解
- 绘制简单2D图形
- 使用WebGL绘制3D图形
图形和动画已经日益成为浏览器中现代 Web 应用程序的必备功能,但实现起来仍然比较困难。视觉上复杂的功能要求性能调优和硬件加速,不能拖慢浏览器。目前已经有一套日趋完善的 API 和工具可以用来开发此类功能。
毋庸置疑,
与浏览器环境中的其他部分一样,
18.1 使用requestAnimationFrame
18.1.1 早期定时动画
虽然使用 setInterval()的定时动画比使用多个 setTimeout()实现循环效率更高,但也不是没有问题。无论 setInterval()还是 setTimeout()都是不能保证时间精度的。作为第二个参数的延时只能保证何时会把代码添加到浏览器的任务队列,不能保证添加到队列就会立即运行。如果队列前面还有其他任务,那么就要等这些任务执行完再执行。简单来讲,这里毫秒延时并不是说何时这些代码会执行,而只是说到时候会把回调加到任务队列。如果添加到队列后,主线程还被其他任务占用,比如正在处理用户操作,那么回调就不会马上执行。
18.1.2 时间间隔问题
知道何时绘制下一帧是创造平滑动画的关键。直到几年前,都没有办法确切保证何时能让浏览器把下一帧绘制出来。随着
18.1.3 requestAnimationFrame
requestAnimationFrame()方法接收一个参数,此参数是一个要在重绘屏幕前调用的函数。这个函数就是修改DOM样式以反映下一次重绘有什么变化的地方。为了实现动画循环,可以把多个requestAnimatitonFrame()调用串联起来,就像以前使用setTimeout()时一样
1 | function updateProgress() { |
第19章 表单脚本
本章内容
- 理解表单基础
- 文本框验证与交互
- 使用其他表单控件
19.1 表单基础
Web 表单在 HTML 中以
