秋招笔试记录
2025-07-20 虾皮
1. Promise性质及静态方法
| 方法 | 描述 | 示例 |
|---|---|---|
Promise.resolve(value) |
用于创建一个已完成状态(fulfilled)的的Promise | Promise.resolve(42).then(console.log) |
Promise.reject(reason) |
快速创建一个已拒绝状态(rejected)的的Promise | Promise.reject('出错了').catch(console.error) |
Promise.all(iterable) |
并发执行多个Promise,全部成功才返回结果数组,如果有一个失败,立即reject | Promise.all([Promise.resove(1), Promise.resolve(2)]).then(console.log) |
Promise.race(iterable) |
多个Promise,第一个settle(无论成功或失败)的结果就是最终结果 | Promise.race([new Promise(res => setTimeout(() => res(1), 100)), new Promise(res => setTimeout(() => res(2), 200)) ]).then(console.log); // 输出:1 |
Promise.allSettled(iterable) |
并发执行多个Promise,等待所有任务都settle(成功或失败),返回所有结果对象数组 | Promise.allSettled([ Promise.resolve(1), Promise.reject('error')]).then(console.og);/*[ { status: "fulfilled", value: 1 }, { status: "rejected", reason: "error" }]* |
Promise.any(iterabel) |
多个Promise,只要有一个成功就resolve,否则返回一个AggregateError |
Promise.any Promise.reject('失败1'),Promise.resolve('成功')]).then(console.log); // 输出:"成功 |
2. CSS视觉格式化模型——浮动
属性值的计算过程
层叠
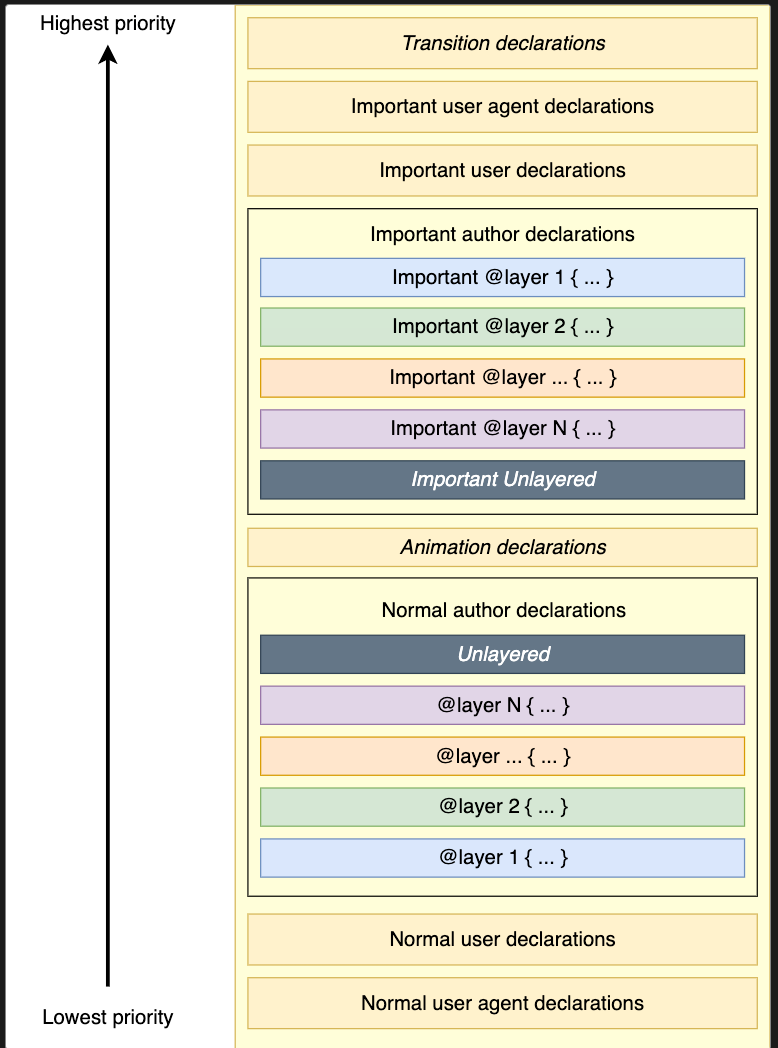
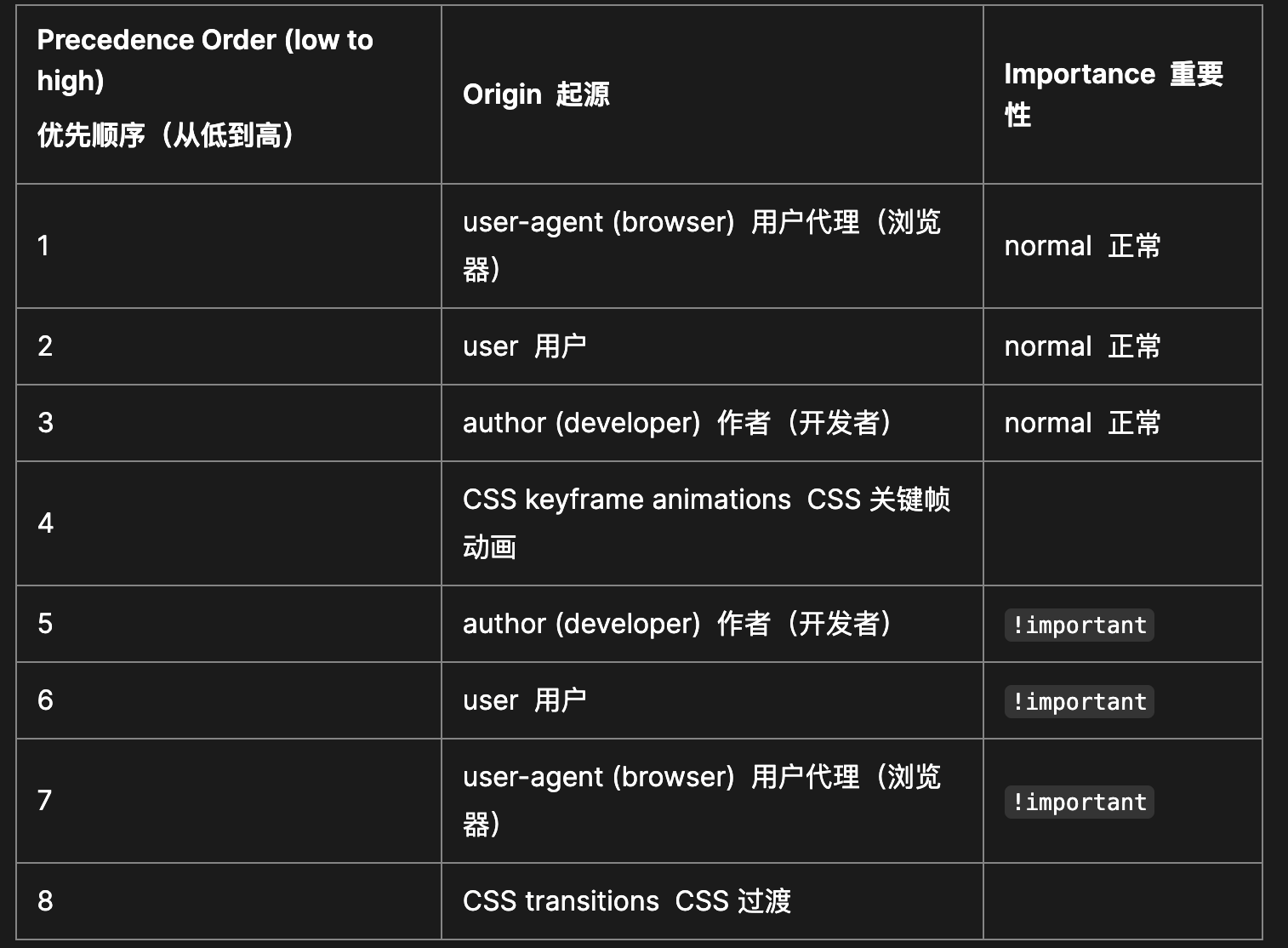
3. 属性值的计算过程——继承
子元素会继承父元素的某些CSS属性。通常,跟文字内容相关的属性都能被继承。
4. 哈希表
计算过程,装填因子:装入的元素数/数组长度
5. 操作系统权限
内核不能调度的是:
- 内核线程
- 用户线程
- 进程
正确答案是进程。
调度(Scheduling) 是操作系统分配 CPU 给不同执行单元(线程)的机制。
内核线程(Kernel Thread)✅ 能被调度内核线程是由操作系统内核管理的线程。操作系统通过调度器(如 Linux 的 CFS)直接对它们进行调度。它有自己的线程控制块(TCB)和内核栈,可以独立运行在 CPU 上。能被调度,是调度的基本单位之一。
用户线程(User Thread)✅ 能被调度(间接)用户线程是在用户空间由线程库(如 pthread)实现的线程。它不直接被操作系统调度,而是通过一个或多个内核线程支持运行。比如 M:N 模型中,多个用户线程复用一个或多个内核线程。所以用户线程虽然不直接由内核调度,但可以间接被调度运行。
进程(Process)❌ 不能被调度进程是资源(如内存、文件描述符等)的拥有者,不是 CPU 调度的直接单位。调度的是进程内部的线程(通常是主线程),而不是整个进程对象。没有线程的进程不会被调度,也就不会运行。
6. HTTP
HTTP如何更新数据: PUT方法
HTTP2有哪些新特性,如何实现的?
- 二进制分帧协议(Binary Framing)
- 将HTTP/1.x的文本格式通信改为二进制帧传输,每个帧包含类型标识,长度,标志位和流ID*。
- 实现原理
- 数据被拆分为更小的帧(如
HEADERS帧承载头部,DATA帧承载正文) - 应用层与传输层之间新增二进制分帧层,对上层保留HTTP语义(方法,状态码不变),下层实现高效解析
- 数据被拆分为更小的帧(如
- 优势:避免文本解析其意义,提升处理效率,并为多路复用奠定基础。
- 多路复用(Multiplexing)
- 特性:单TCP连接上并行传输多个请求/响应,解决队头阻塞问题
- 实现原理
- 引入流(Streaming)的概念:每个请求/响应分配唯一流ID(奇数由客户端发起,偶数由服务器发起)
- 不同流的帧可以乱序发送,接收端按流ID重组
- 通过帧头的
END_STREAM标志标记流结束
- 优势:减少TCP连接数量(从HTTP/1.1的6-8个降低至1个),降低延迟,提高带宽利用率。
- 头部压缩(HPACK)
- 特性:使用HPACK算法压缩头部,减少冗余数据传输
- 实现原理:
- 静态表:内置61个常用字段(如:
method: GET对应索引2) - 动态表:运行时逐步更新,存储新字段(如
user-agent首次发送后分配索引62) - 哈夫曼表:对字符串进一步压缩(如URL路径)
- 静态表:内置61个常用字段(如:
- 优势:头部大小减少50%-90%,显著减低延迟
- 服务器推送(Server Push)
- 特性:服务端可以主动推送资源到客户端缓存(如CSS, JS)到客户端缓存,无需客户端显式请求。
- 实现原理
- 客户端请求资源A时,服务端通过
PUSH_PROMISE帧预告推送资源B; - 客户端可发送
RST_STREAM帧拒绝推送。 - 推送资源需遵守同源策略。
- 客户端请求资源A时,服务端通过
- 优势:减少额外RTT(往返延迟),加速页面渲染。
- 请求优先级与流量控制
- 优先级(priority)
- 流可以设置权重(1-256)和依赖关系,构建优先级树
- 服务端优先处理高权重流(如CSS/JS优先与图片)
- 流量控制(Flow Control)
- 类似TCP滑动窗口:通过WINDOW_UPDATE帧动态调整流的数据量
- 仅DATA帧受控制,避免单一流耗尽带宽
- 优先级(priority)
6. 子网掩码
7. 排序算法
下面那种排序方法最适合链表?D.归并排序
A. 插入排序
B. 冒泡排序
C. 快速排序
D. 归并排序
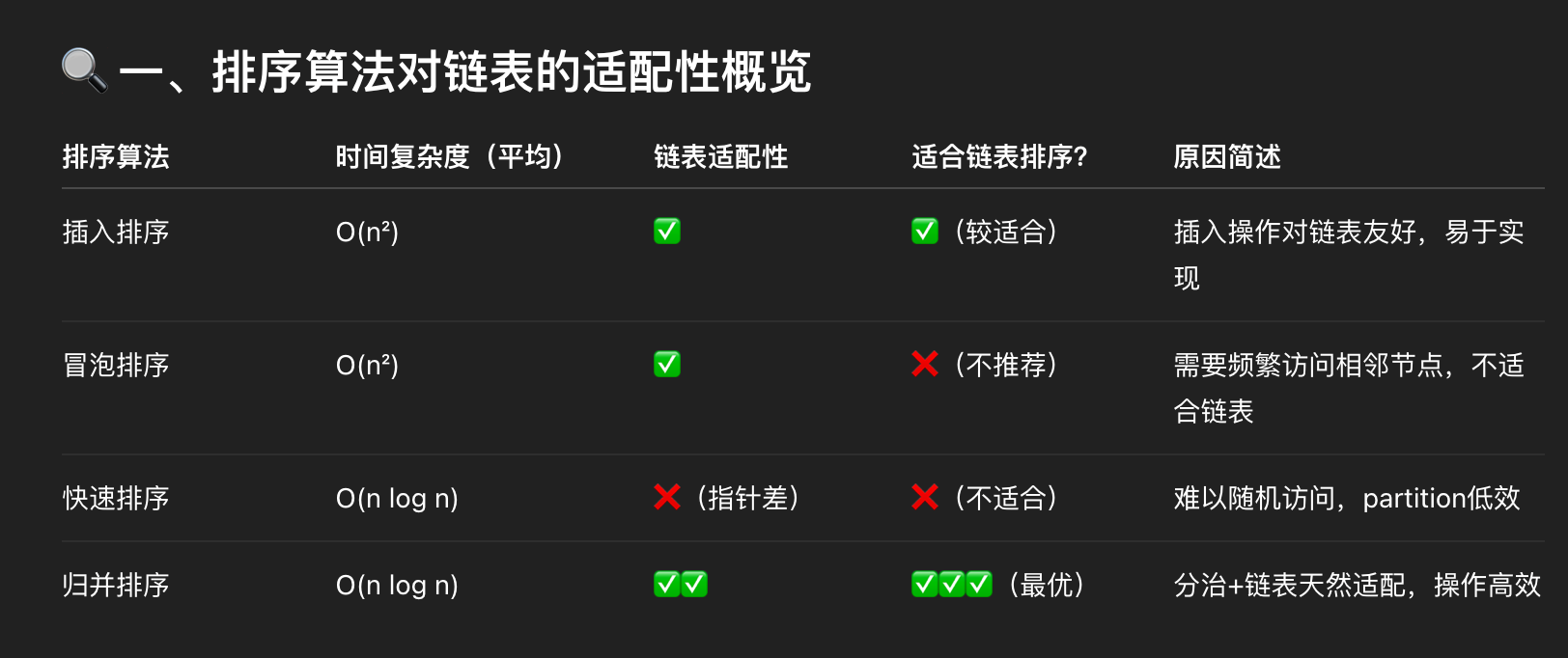
归并排序的思想是“分成两半,递归排序,再合并”:1
A → B → C → D → E → F
切成两半:1
2A → B → C
D → E → F
各自排序 → 合并成有序链表
用 快慢指针 就能找到中点,O(n) 时间内分裂链表;
合并两个有序链表也很简单,只需重排指针,无需大量内存拷贝;
所有操作都是线性指针操作,不需要随机访问。
8. 概率论
9. 预检请求
那种情况下会发出预检请求? BD
A. POST: multipart/form-data
B. POST: application/xml
C. POST: text/plain
D. PUT
预检请求(Preflight Request)是 跨域资源共享(CORS, Cross-Origin Resource Sharing) 机制的一部分,是浏览器在发起某些跨域请求之前,为了保证服务器允许这个请求而“预先”发送的一个 OPTIONS 请求,用于探测实际请求是否被允许。
🔍 什么是预检请求?
当一个跨域请求 不属于简单请求(simple request),浏览器会自动先发送一个 预检请求(OPTIONS 请求),询问服务器:
“我接下来打算用这种方式来请求你(比如带有特殊头、非 GET/POST、带凭据等),你允许吗?”
如果服务器回应允许,浏览器才会继续发送正式的请求。
✅ 简单请求的定义(不会触发预检):
满足以下三个条件的请求被称为 简单请求(simple request),不会触发预检请求:
请求方法是:
GETHEADPOST
请求头限制在以下几种:
AcceptAccept-LanguageContent-LanguageContent-Type(但其值仅限于:text/plainmultipart/form-dataapplication/x-www-form-urlencoded)
请求中 没有携带凭据(
credentials: include)
🚩 哪些情况会触发预检请求?
只要不满足“简单请求”的条件,就会触发预检请求,常见情形有:
| 触发情况 | 描述 | 示例 |
|---|---|---|
| ✅ 自定义请求头 | 如设置了 Authorization、X-Custom-Header 等 |
fetch('/api', { headers: { 'X-Token': 'abc' } }) |
| ✅ 请求方法非 GET/HEAD/POST | 比如使用了 PUT、DELETE、PATCH |
fetch('/api', { method: 'DELETE' }) |
✅ Content-Type 不符合要求 |
如使用 application/json |
fetch('/api', { method: 'POST', headers: { 'Content-Type': 'application/json' } }) |
| ✅ 携带 Cookie 或身份认证信息 | 设置了 credentials: include 或 withCredentials: true |
fetch('/api', { credentials: 'include' }) |
🛠 示例说明
✅ 示例 1:不会触发预检请求(简单请求)
1 | fetch('https://api.example.com/data', { |
满足所有简单请求条件,所以不会触发预检。
❌ 示例 2:会触发预检请求
1 | fetch('https://api.example.com/data', { |
原因:Content-Type 是 application/json,不属于简单请求的 Content-Type,因此触发预检。
❌ 示例 3:会触发预检请求
1 | fetch('https://api.example.com/data', { |
原因:使用了 PUT 方法,并添加了 Authorization 头,两者都违反简单请求规则。
🌐 预检请求过程(请求和响应)
请求(浏览器自动发出的 OPTIONS 请求):
1 | OPTIONS /data |
服务器响应(若允许):
1 | 204 No Content |
📌 开发建议
若你不希望频繁发出预检请求(提升性能),可以尽量:
- 使用 简单请求的格式
- 不设置自定义头部
- 避免使用
application/json,使用application/x-www-form-urlencoded替代 - 不使用非标准方法(如
PUT,DELETE)
如有需要我可以帮你写个测试用例或浏览器调试指南。要吗?
10. localhost和127.0.0.1是什么关系?
localhost 和 127.0.0.1 的关系,可以简单理解为:
1. 它们都指向“本地回环地址”(Loopback Address)
127.0.0.1是 IPv4 回环地址的标准地址,表示本机(自己电脑)的网络接口。localhost是一个主机名(hostname),通常被映射(解析)到127.0.0.1,也就是本机地址。
2. 具体区别和联系
| 项目 | 说明 |
|---|---|
127.0.0.1 |
IPv4 回环地址,是一个具体的 IP 地址。 |
localhost |
一个主机名,通常映射到 127.0.0.1(IPv4)或 ::1(IPv6)。 |
3. 它们的对应关系
在大多数操作系统里,
localhost会在 hosts 文件 中被解析为127.0.0.1,路径例如:- Windows:
C:\Windows\System32\drivers\etc\hosts - Linux / macOS:
/etc/hosts
- Windows:
示例内容:
1 | 127.0.0.1 localhost |
4. 应用
- 当你在浏览器或程序里访问
http://localhost,系统会先查找localhost的 IP,通常会解析成127.0.0.1,然后向本机网络接口发送请求。 - 访问
http://127.0.0.1则是直接使用 IP,不需要解析主机名。
5. 补充
localhost也可能在某些网络配置中被改成别的 IP 地址,但几乎所有默认配置都会指向127.0.0.1。127.0.0.1只是 IPv4 的回环地址,IPv6 对应的是::1。
总结:
localhost是一个主机名,通常解析为回环 IP 地址127.0.0.1,二者最终都指向本机,方便开发和测试时访问本机服务。
需要的话,我可以帮你演示如何查看和修改 hosts 文件,或者用命令行测试 localhost 和 127.0.0.1 的网络连通性。要吗?
11. GET和POST的区别?
好的,下面给你详细列举 HTTP 协议中 GET 和 POST 两种请求方法 的所有主要区别,并用示例说明它们的不同点。
GET 和 POST 的区别详解
| 序号 | 区别点 | GET | POST | 说明与举例 |
|---|---|---|---|---|
| 1 | 请求目的 | 获取资源(请求数据) | 提交数据(发送数据给服务器) | GET 用于取数据,如请求网页;POST 用于提交表单、上传数据 |
| 2 | 请求参数位置 | URL 中的查询字符串(Query String) | 请求体(Request Body) | GET 请求参数在 URL 后面,POST 在请求体中 |
| 3 | 请求参数大小 | 有限制(浏览器和服务器限制 URL 长度) | 无明显限制(受服务器配置影响较大) | URL 长度有限制,一般 2k-8k 字符,POST 请求体大多数没限制 |
| 4 | 安全性 | 参数暴露在 URL,较不安全 | 参数在请求体,较安全 | GET 参数易被缓存、日志记录、浏览器历史记录等看到 |
| 5 | 幂等性 | 幂等(多次请求效果相同) | 不一定幂等 | GET 请求多次不会改变服务器资源;POST 多次提交可能会创建多个资源 |
| 6 | 缓存机制 | 默认会被缓存 | 不会被缓存(需要服务器显式设置缓存) | GET 请求可被浏览器或代理缓存,POST 一般不会缓存 |
| 7 | 浏览器历史记录 | 会保存 | 不会保存 | GET 请求会记录在浏览器地址栏历史中,方便回退 |
| 8 | 书签支持 | 支持(URL 可直接书签) | 不支持 | POST 参数放在请求体,无法保存为书签 |
| 9 | 编码格式 | URL 编码(application/x-www-form-urlencoded) | 多种编码格式,默认同 GET,但可上传文件(multipart/form-data) | POST 支持复杂数据格式和文件上传 |
| 10 | 请求体内容 | 无请求体 | 有请求体 | GET 不能有请求体,POST 必须有请求体 |
| 11 | 服务器处理 | 服务器根据 URL 和参数返回数据 | 服务器根据请求体内容处理数据 | GET 是查询,POST 通常是写入或修改 |
| 12 | 浏览器限制 | URL 长度限制 | 无 URL 长度限制 | POST 允许发送更大数据,GET 参数受限 |
| 13 | 请求示例 | GET /search?q=chatgpt HTTP/1.1 |
POST /submit HTTP/1.1 (body: name=xx) |
举例见下文 |
| 14 | 调用方式 | 主要用于请求数据 | 主要用于发送数据 | GET 适合安全无副作用操作,POST 用于提交数据或有副作用操作 |
| 15 | 协议约定 | 可被缓存、被收藏、保留历史记录 | 不能被缓存、不能被收藏、不会保留历史记录 | HTTP 协议的推荐行为 |
具体示例说明
1. GET 请求示例
1 | GET /search?q=chatgpt&page=1 |
- 参数
q=chatgpt&page=1拼接在 URL 中。 - 适合请求服务器数据,比如搜索结果。
- 浏览器地址栏直接显示所有参数,支持收藏和分享。
2. POST 请求示例
1 | POST /submit |
- 参数放在请求体中,不显示在 URL。
- 适合提交登录表单、上传文件等。
- 参数对用户不可见,安全性稍好。
3. 功能差异举例
查询用户信息
GET:
1
GET /user?id=123 HTTP/1.1
服务器返回用户 ID 为 123 的信息,安全且幂等。
更新用户信息
POST:
1
2
3
4POST /user/update HTTP/1.1
Content-Type: application/json
{ "id": 123, "name": "Jack" }服务器更新用户信息,非幂等,多次提交可能会重复操作。
额外补充
- 非幂等操作的例外:有些服务器会把 POST 当幂等使用,但标准不保证。
使用场景建议:
- GET:获取资源、搜索、导航链接。
- POST:提交表单、上传数据、创建资源。
总结
| 特点 | GET | POST |
|---|---|---|
| 参数位置 | URL 查询字符串 | 请求体 |
| 可见性 | URL 可见 | 请求体不可见 |
| 数据大小 | 有限制(URL 长度限制) | 几乎无大小限制 |
| 幂等性 | 是 | 否(一般情况) |
| 安全性 | 较低(暴露在 URL) | 较高 |
| 缓存 | 支持缓存 | 不支持缓存 |
| 浏览器历史 | 有 | 无 |
| 书签支持 | 支持 | 不支持 |
| 用途 | 获取数据、查询 | 发送数据、提交表单 |
如果你需要,我也可以帮你写一份基于 fetch 或 axios 的代码示例对比,或者帮你分析在实际开发中如何选择用 GET 还是 POST。你要吗?
12. 无向图的深度优先搜索
13. HTTPS涉及的加密技术有哪些?
A. 散列函数
B. 对称加密
C. 非对成加密
D. 数字签名
HTTPS 涉及的加密技术主要包括以下几种:
A. 散列函数(Hash Function)
用于生成消息摘要,保证数据完整性。B. 对称加密(Symmetric Encryption)
用于加密传输的数据,速度快,保证数据保密性。C. 非对称加密(Asymmetric Encryption)
用于密钥交换和身份验证,保证安全的密钥传递。D. 数字签名(Digital Signature)
用于身份认证和数据不可否认性。
所以,HTTPS 涉及的加密技术是:
A、B、C、D 全部都涉及。
具体说明:
- 散列函数:计算消息摘要,检测数据是否被篡改。
- 对称加密:用协商好的对称密钥对通信内容加密。
- 非对称加密:用公钥加密、私钥解密,用于安全交换对称密钥。
- 数字签名:用私钥对数据签名,验证身份和数据完整性。
如果你需要,我可以帮你写一段关于 HTTPS 握手流程中这些加密技术如何协同工作的简单解释,或者画个流程图。要吗?
14. ACM输入输出
1 | const rl = require("readline").createInterface({ |
15. 判断一个数是不是质数?
 微信
微信 支付宝
支付宝
